Библиотека сайта rus-linux.net
ITK
Глава 9 из книги "Архитектура приложений с открытым исходным кодом", том 2.Оригинал: ITK
Авторы: Luis Ibanez, Brad King
Перевод: А.Панин
Иерархия классов конвейера
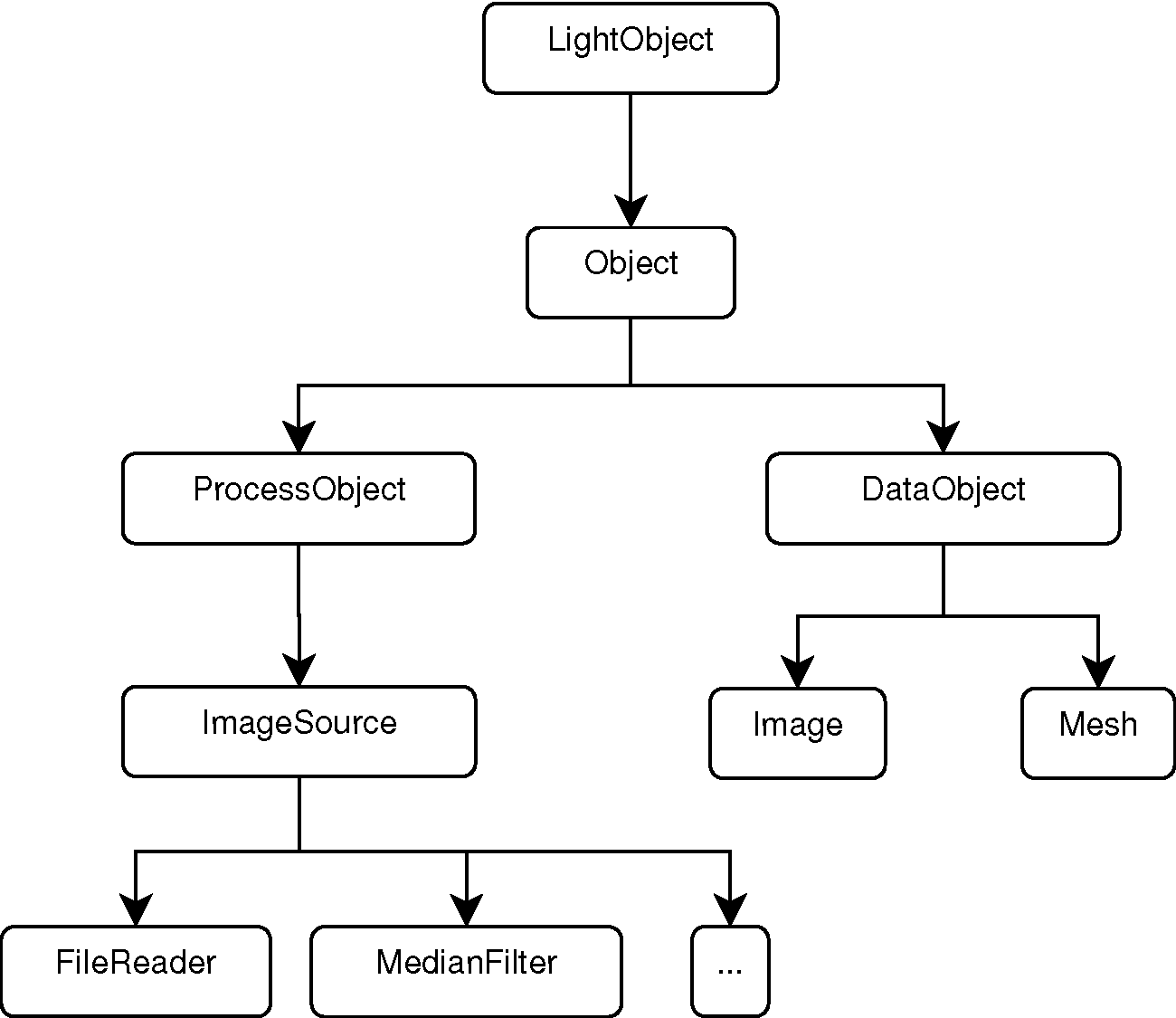
Рисунок 9.6: Иерархия классов ProcessObject и DataObject
Начальное проектирование и реализация конвейера данных фреймворка ITK происходили по аналогии с Visualization Toolkit (VTK), развитым проектом на момент начала разработки ITK. (Обратитесь к тому 1 книги "Архитектура приложений с открытым исходным кодом").
На Рисунке 9.6 показана иерархия объектов конвейера ITK. В частности следует отметить взаимосвязь между основными объектами Object, ProcessObject, DataObject, некоторыми классами из семейства фильтров и семейства хранилищ данных. В рамках данной абстракции любой объект, который предназначен для передачи фильтру или создается в ходе вывода данных фильтром, должен наследоваться от класса DataObject. Все фильтры, которые выводят и принимают данные должны наследоваться от класса ProcessObject. Механизмы обмена информацией о данных, требуемые для передачи данных по конвейеру, реализованы частично в рамках класса ProcessObject и частично в рамках класса DataObject.
Классы LightObject и Object являются иллюстрацией дихотомии классов ProcessObject и DataObject. Классы LightObject и Object предоставляют такие стандартные функции, как API для обмена объектами Events и средства поддержки многопоточности.
Внутренние процессы конвейера
На Рисунке 9.7 представлена UML-диаграмма последовательности вызовов, описывающая взаимодействия между объектами ProcessObject и DataObject в рамках упрощенного конвейера, состоящего из объектов ImageFileReader, MedianImageFilter и ImageFileWriter.
- Обновление информации о выходных данных (обратная последовательность вызовов)
- Обновление запрошенного фрагмента изображения (обратная последовательность вызовов)
- Обновление выходных данных (обратная последовательность вызовов)
- Генерация данных (прямая последовательность вызовов)
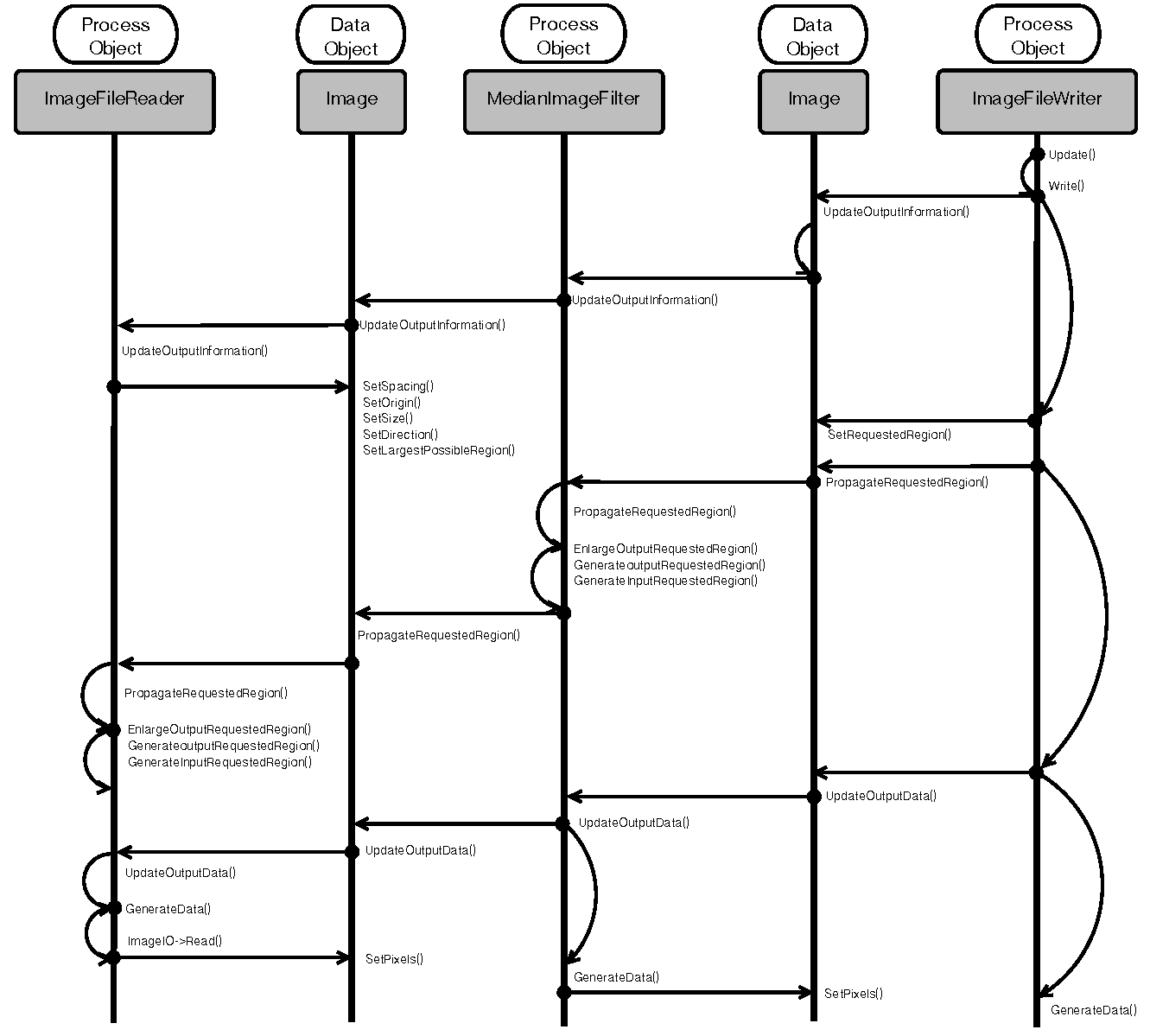
Рисунок 9.7: UML-диаграмма последовательности вызовов
Процесс работы конвейера начинается с вызова приложением метода Update() последнего фильтра конвейера; в этом конкретном примере этот фильтр представлен объектом ImageFileWriter. Вызов метода Update() инициирует первую обратную последовательность вызовов. Это последовательность, которая начинается с последнего фильтра конвейера и распространяется в направлении первого фильтра.
Целью первой фазы является получение ответа на вопрос "Как много данных будет сгенерировано?" В форме кода этот вопрос реализован в рамках метода UpdateOutputInformation(). С помощью этого метода каждый фильтр рассчитывает объем данных изображения, который может быть получен на выходе в случае обработки заданного исходного объема данных. Учитывая то, что объем исходных данных должен быть известен до того, как фильтр сможет дать ответ на вопрос об объеме выходных данных, вопрос должен переадресовываться предыдущим фильтрам до того момента, как будет достигнут исходный фильтр, который может самостоятельно ответить на вопрос. В этом конкретном примере исходный фильтр представлен объектом ImageFileReader. Этот фильтр может установить объем выходных данных, получив информацию из файла изображения, который был выбран для чтения. После того, как первый фильтр конвейера отвечает на поставленный вопрос, последующие фильтры один за другим получают возможность вычисления соответствующих объемов выходных данных до того момента, как последний фильтр конвейера вычислит этот объем.
Вторая фаза, в ходе которой вызовы также осуществляются против направления конвейера, предназначена для информирования фильтров об объеме выходных данных, который они должны сгенерировать в ходе работы конвейера. Концепция запрашиваемых фрагментов (Requested Region) необходима для поддержки потоковой обработки данных в ITK. Она позволяет сообщать фильтрам конвейера о том, что не следует генерировать полное изображение, а следует обрабатывать только его фрагмент, являющийся запрашиваемым фрагментом. Это очень полезно в том случае, если имеющееся изображение не может быть полностью помещено в доступную оперативную память системы. Вызовы направлены от последнего фильтра к первому, причем каждый промежуточный фильтр модифицирует размер запрашиваемого фрагмента с учетом необходимых дополнительных границ исходного изображения, которые могут понадобиться фильтру для генерации фрагмента изображения заданного размера. В этом конкретном примере медианный фильтр обычно добавляет границу толщиной в 2 пикселя к исходному изображению. Таким образом, если фильтр записи запрашивает фрагмент размером 500 x 500 пикселей у медианного фильтра, медианный фильтр в свою очередь запросит фрагмент размером 502 x 502 пикселя у фильтра чтения, так как медианному фильтру с настройками по умолчанию требуется фрагмент размером 3 x 3 пикселя для вычисления значения одного пикселя результирующего изображения. Эта фаза реализована в форме кода в рамках метода PropagateRequetedRegion().
Третья фаза направлена на запуск выполнения расчетов в отношении данных запрошенного фрагмента. В ходе этой фазы вызовы также осуществляются против направления конвейера, а в форме кода она реализована в рамках метода UpdateOutputData(). Так как каждому фильтру требуются исходные данные для обработки и формирования выходных данных, вызовы изначально передаются предшествующим соответствующим фильтрам, что подразумевает распространение вызовов против направления конвейера. После возврата данных предыдущим фильтром, текущий фильтр приступает непосредственно к их обработке.
Четвертая и финальная фаза предусматривает выполнение вызовов по направлению конвейера и заключается в непосредственной обработке данных каждым из фильтров. В форме кода эта фаза представлена в рамках метода GenerateData(). Направление, совпадающее с направлением конвейера, является последствием не того, что каждый фильтр осуществляет вызовы методов следующего фильтра, а того факта, что вызовы UpadateOutputData() осуществляются в последовательности от первого к последнему фильтру конвейера. Таким образом, все вызовы осуществляются в направлении конвейера в соответствии со временем вызовов, а не в соответствии с тем, какой фильтр осуществляет запросы. Это пояснение важно, так как конвейер ITK соответствует концепции Pull Pipeline, в которой данные запрашиваются с конца конвейера и управление логикой осуществляется также с конца конвейера.
Продолжение статьи: Фабрики