Библиотека сайта rus-linux.net
Ошибка базы данных: Table 'a111530_forumnew.rlf1_users' doesn't exist
Как на Linux настроить RAID 10 для достижения высокой производительности и отказоустойчивости дискового ввода / вывода
Оригинал: How to set up RAID 10 for high performance and fault tolerant disk I/O on LinuxАвтор: Gabriel Canepa
Дата публикации: September 29, 2014
Перевод: Н.Ромоданов
Дата перевода: февраль 2015 г.
Массив RAID 10, т. е. RAID 1 + 0 или чередование с зеркалированием, обеспечивает высокую производительность и отказоустойчивость дисковых операций ввода / вывода за счет объединения функций из RAID 0, в котором операции чтения / записи выполняются параллельно на нескольких дисках, и RAID 1, в котором данные записываются идентично на двух или более дисках.
В настоящем руководстве я покажу, как создать программный массив RAID 10, используя для этого пять одинаковых дисков по 8 ГБ. Хотя минимальное количество дисков для создания массива RAID 10 равно четырем (например, комплект с чередованием из двух зеркал), мы добавим дополнительный запасной диск на случай, если один из главных дисков выйдет из строя. Мы также будем пользоваться некоторыми инструментальными средствами, которые в дальнейшем можно будет применить для анализа производительности вашего массива RAID.
Пожалуйста, обратите внимание, что обсуждение вопросов о всех плюсах и минусах RAID 10 и других схем построения массивов дисков (с дисками разных размеров и разными файловыми системами) выходит за рамки этой статьи.
Как работает массив RAID 10?
Если вам нужно реализовать решение по хранению данных, в котором поддерживаются интенсивные операции ввода / вывода (например, база данных, электронная почта и веб-серверы), то можно сделать с помощью RAID 10. Позвольте мне рассказать, каким образом это сделать. Обратимся к следующей картинке.
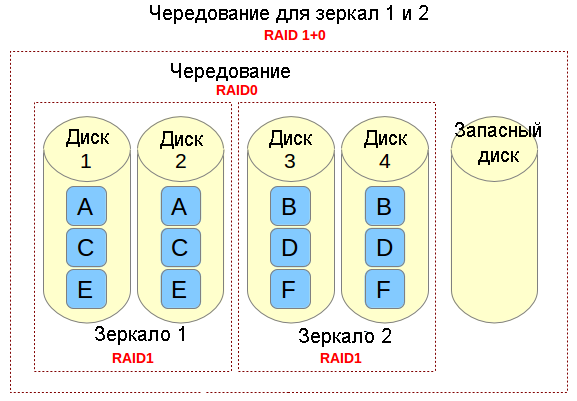
Представьте себе файл, который состоит из блоков данных A, B, C, D, E и F так, как это показано на рисунке выше. Каждый набор зеркал RAID-1 (например, Зеркало 1 или 2) реплицирует блоки на каждом из его двух устройств. Из-за такой конфигурации скорость записи уменьшается, поскольку каждый блок должен быть записан два раза, по одному разу для каждого диска, тогда как производительность по чтению остается неизменной по сравнению с чтением из отдельных дисков. Преимущество состоит в том, что при такой настройке обеспечивается избыточность, так что если произойдет сбой более чем с одним из дисков в каждом зеркале, будет сохранена поддержка выполнения обычных операций дискового ввода / вывода.
Чередование в RAID 0 представляет собой деление данных на блоки и одновременная запись блока A в зеркале 1, блока B в зеркале 2 (и так далее), что улучшает общую производительность чтения и записи. С другой стороны, ни в одном из зеркал не содержится вся информация любой части данных, если рассматривать весь основной набор данных. Это означает, что если сбой произойдет в одном из зеркал, то весь набор RAID 0 (и, следовательно, набор RAID 10) станет неработоспособным с безвозвратной утратой данных.
Настройка массива RAID 10
Есть два возможных способа настройки массива RAID 10: одношаговый (когда массив создается сразу) или последовательный (состоит из создания двух или большего количества массивов RAID 1, а затем использования их в качестве компонентов устройств в RAID 0). В этой статье мы рассмотрим одношаговый вариант создания массива RAID 10, поскольку он позволяет нам создавать массив из четного или нечетного количества дисков, и предоставляет возможность управлять массивом RAID как единым устройством, в отличие от последовательного варианта (в котором допускается только четное число дисков и управление будет осуществляется последовательно, по-отдельности для RAID 1 и RAID 0).
Предполагается, что вы установили пакет mdadm и в вашей системе работает демон. Подробности смотрите в следующем руководстве. Также предполагается, что на каждом диске был создан первичный раздел sd[bcdef]1. Таким образом, команда:
ls -l /dev | grep sd[bcdef]
должна выдать следующий результат:

Давайте пойдем дальше и создадим массив RAID 10 с помощью следующей команды:
# mdadm --create --verbose /dev/md0 --level=10 --raid-devices=4 /dev/sd[bcde]1 --spare-devices=1 /dev/sdf1

Когда массив создан (на это должно пойти более нескольких минут), то команда:
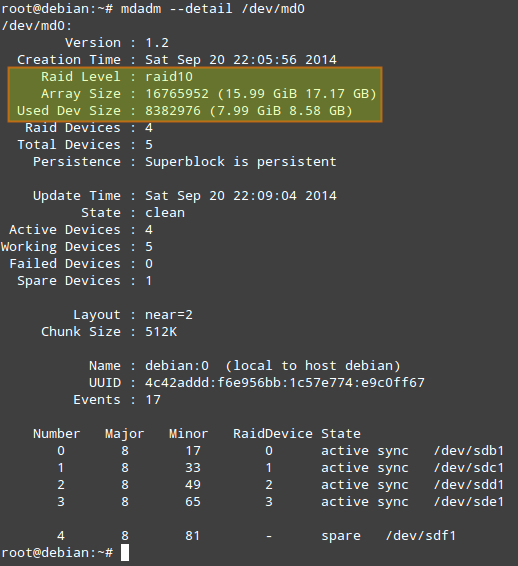
# mdadm --detail /dev/md0
должна выдать следующий результат:
Прежде, чем мы продолжим, необходимо отметить следующее.
- Used Dev Space указывает для каждого устройства емкость, используемую под массив.
- Array Size указывает общий размер массива. Для массива RAID 10, это значение равно (N*C)/M, где N - количество активных устройств, C - емкость активных устройств, M - количество устройств в каждом зеркале. Таким образом, в данном случае (N*C)/M равно (4*8ГБ)/2 = 16ГБ.
- В Layout указываются конкретные особенности размещения данных. Возможные значения здесь следующие.
- n (параметр, используемый по умолчанию): означает near copies (близко расположенные копии). Различные копии одного и того же блока данных имеют в различных устройствах аналогичные смещения. Такая компоновка позволяет получить аналогичные скорости чтения и записи, как и в массиве RAID 0.
- o означает offset copies (смещение копий). Вместо того, чтобы дублировать куски данных в отдельной полосе, дублируются целые полосы, но они на каждом устройстве сдвинуты, так что дублируемые блоки находятся на разных устройствах с разными смещениями. Т.е. следующая копия на следующем диске находится на один фрагмент данных дальше. Чтобы использовать эту компоновку в вашем массиве RAID 10, добавьте параметр --layout=o2 в команду, с помощью которой создается массив.

- f означает far copies (копии с сильно различающимися смещениями). Такая компоновка обеспечивает более высокую производительность чтения, но худшую производительность записи. Таким образом, это самый лучший вариант для систем, в которых операции чтения должны выполняться гораздо чаще операций записи. Чтобы использовать эту компоновку в вашем массиве RAID 10, добавьте параметр --layout=f2 в команду, с помощью которой создается массив.
Число, которое расположено за n, f и o в параметре --layout, указывает какое количество копий необходимо для каждого блока данных. Это значение по умолчанию равно 2, но оно может быть в диапазоне от 2 и до числа, равному количеству устройств в массиве. Указывая правильное количество копий, вы можете минимизировать влияние операций ввода/вывода на каждый отдельный диск.
- n (параметр, используемый по умолчанию): означает near copies (близко расположенные копии). Различные копии одного и того же блока данных имеют в различных устройствах аналогичные смещения. Такая компоновка позволяет получить аналогичные скорости чтения и записи, как и в массиве RAID 0.
- Величина Chunk Size, согласно определению из вики Linux RAID, представляет собой наименьшую порцию данных, которые могут записываться на диски. Оптимальный размер порции зависит от скорости операций ввода / вывода и размеров файлов. В случае наличия больших файлов накладные расходы будут меньшими при довольно больших размерах порций, тогда как для массивов, в которых в основном небольшие файлы, преимущество может быть достигнуто при небольших размерах порции данных. Чтобы указать конкретный размер порции данных для вашего массива RAID 10, добавьте параметр --chunk=desired_chunk_size в команду, которая используется при создании массива.
К сожалению, нет формулы расчета размера порции данных, которая бы позволила повысить производительность во всех случаях. Ниже приводится несколько рекомендаций, которые нужно учитывать.
- Файловая система: обычно считают, что лучшей является файловая система XFS, но хорошим выбором будет и EXT4.
- Оптимальная компоновка: когда порции данных расположены далеко друг от друга, то это улучшает производительность при чтении, но ухудшает производительность при записи.
- Количество копий: большее количество копий минимизирует влияние операций ввода / вывода, но увеличивает издержки, поскольку необходимо больше дисков.
- Аппаратура: SSD, скорее всего, будет обеспечивать большую производительность (при одних и тех же условиях), чем традиционные (шпиндельные) диски.
Тестируем производительность RAID при помощи DD
Для проверки производительности нашего массива RAID 10 (/dev/md0) можно использовать следующие тесты.
1. Операция записи
На устройство записывается один файл размером 256 МБ:
# dd if=/dev/zero of=/dev/md0 bs=256M count=1 oflag=dsync
1000 раз записываются 512 байта:
# dd if=/dev/zero of=/dev/md0 bs=512 count=1000 oflag=dsync
Когда установлен флаг dsync, то команда dd не использует кэш файловой системы и выполняет синхронизированную запись в массив RAID. Этот флаг используется для устранения эффекта кэширования во время тестирования производительности RAID.
2. Операция чтения
256KiB*15000 (3.9 GB) копируются из массива в /dev/null:
# dd if=/dev/md0 of=/dev/null bs=256K count=15000
Тестируем производительность RAID при помощи Iozone
Iozone является инструментальным средством тестирования, с помощью которого можно измерять различные дисковые операции ввода/вывода, в том числе чтение/запись в случайном порядке, последовательное чтение/запись и повторное чтение/повторную запись. Он позволяет экспортировать результаты в файл Microsoft Excel или LibreOffice Calc.
Установка пакета Iozone на CentOS/RHEL 7
Включите Repoforge. Затем:
# yum install iozone
Установка пакета Iozone на Debian 7
# aptitude install iozone3
Команда iozone, указанная ниже, выполнит все тесты с массивом RAID-10:
# iozone -Ra /dev/md0 -b /tmp/md0.xls
- -R: генерирует результат в виде отчета в формате, совместимом с Excel.
- -a: запускает команду iozone в полностью автоматическом режиме с выполнением всех тестов и с записью записей/файлов всех необходимых размеров. Размеры записей: 4k-16M; и размеры файлов: 64k-512М.
- -b /tmp/md0.xls: указывает сохранять результаты тестирования в определенном файле.
Надеюсь, что эта статья окажется полезной. Вы можете добавить свои размышления или посоветовать, как улучшить производительность RAID 10.