Библиотека сайта rus-linux.net
Начинаем программировать на языке ассемблера
Оригинал: Get started in assembly language. Part 1
Автор: Mike Saunders
Дата публикации: 30 октября 2015 г.
Перевод: А.Панин
Дата перевода: 10 ноября 2015 г.
Часть 1: Преодолеваем ограничения высокоуровневых языков программирования и разбираемся, как на самом деле работает центральный процессор.
Для чего это нужно?
- Для понимания принципов работы компиляторов.
- Для понимания инструкций центрального процессора.
- Для оптимизации вашего кода в плане производительности.
Большинство людей считает, что язык ассемблера мало чем отличается от черной магии и является частью темного и страшного мира, в который рискует войти лишь 0.01% лучших разработчиков программного обеспечения. Но на самом деле это красивый и очень доступный язык программирования. Вам стоит изучить его основы хотя бы для того, чтобы лучше понимать механизм генерации кода компиляторами, принцип работы центральных процессоров, а также лучше представлять принцип работы компьютеров. Язык ассемблера по своей сути является текстовым представлением инструкций, которые исполняет центральный процессор, с некоторыми дополнительными возможностями, упрощающими процесс программирования.
На сегодняшний день никто в здравом уме не станет разрабатывать мощное приложение для настольного компьютера на языке ассемблера. Ведь код такого приложения будет слишком запутанным, процесс отладки приложения будет значительно усложнен, кроме того придется приложить колоссальные усилия, чтобы портировать это приложение для работы с другими архитектурами центральных процессоров. Но при этом язык ассемблера все же используется для различных целей: многие драйверы из состава ядра Linux содержат фрагменты кода на языке ассемблера, который используется как из-за того, что является лучшим языком программирования для непосредственного взаимодействия с аппаратным обеспечением, так и из соображения повышения скорости работы драйверов. Также в определенных случаях код, написанный вручную на языке ассемблера, может работать быстрее кода, сгенерированного компилятором.
В статьях данной серии мы будем подробно исследовать мир языка ассемблера. В данной статье мы рассмотрим лишь базовые приемы программирования, в статье из следующего номера журнала разберемся с более сложными вопросами, после чего закончим рассмотрение языка ассемблера написанием простой загружающейся операционной системы - она не сможет выполнять какой-либо полезной работы, но будет основываться на вашем коде и работать непосредственно с аппаратным обеспечением без необходимости загрузки каких-либо сторонних ОС. Звучит неплохо, не правда ли? Давайте начнем
Ваша первая программа на языке ассемблера
Многие руководства по программированию на языке ассемблера начинаются с длинных, запутанных и утомительных разделов, в которых осуществляется бесконечное рассмотрение вопросов бинарной арифметики и теории проектирования центральных процессоров, причем эти разделы не содержат какого-либо реального кода. Я считаю, что подобные материалы сводят на нет интерес читателя, поэтому мы начнем непосредственно с рассмотрения кода реальной программы. После этого мы рассмотрим каждую из строк кода этой программы для того, чтобы вы поняли принцип работы ассемблера на основе практического примера.
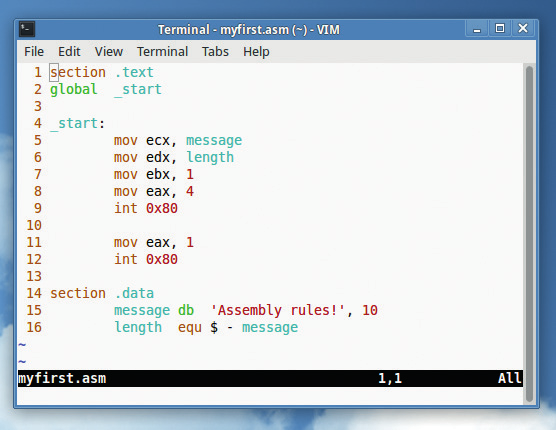
Некоторые текстовые редакторы, такие, как Vim, осуществляют подсветку синтаксиса языка ассемблера (попробуйте использовать команду set syn=nasm)
Скопируйте следующий код в в текстовое поле любого текстового редактора и сохраните его в файле с именем myfirst.asm в вашей домашней директории:
section .text global _start _start: mov ecx, message mov edx, length mov ebx, 1 mov eax, 4 int 0x80 mov eax, 1 int 0x80 section .data message db 'Assembly rules!', 10 length equ $ - message
(Примечание: для отступов в коде вы можете использовать как как символы пробелов, так и символы табуляции - это не имеет значения.) Данная программа просто выводит строку "Assembly rules!" на экран и завершает работу.
Инструмент, который мы будем использовать для преобразования данного кода языка ассемблера в исполняемый бинарный файл носит довольно забавное название "ассемблер". Существует много различных ассемблеров, но моим любимым ассемблером является NASM; он находится в репозитории пакетов программного обеспечения практически любого дистрибутива, поэтому вы можете установить его с помощью менеджера пакетов программного обеспечения с графическим интерфейсом, команды yum install nasm, apt-get install nasm или любой другой команды, актуальной для вашего дистрибутива.
Теперь откройте окно эмулятора терминала и введите следующие команды:
nasm -f elf -o myfirst.o myfirst.asm ld -m elf_i386 -o myfirst myfirst.o
Первая команда предназначена для генерации с помощью NASM (исполняемого) файла объектного кода с именем myfirst.o формата ELF (формат исполняемых файлов, используемый в Linux). Вы можете спросить: "Для чего генерируется файл объектного кода, ведь логичнее сгенерировать файл с инструкциями центрального процессора, которые он должен исполнять?" Ну, вы могли бы использовать исполняемый файл с инструкциями центрального процессора в операционных системах 80-х годов, но современные операционные системы предъявляют больше требований к исполняемым файлам. Бинарные файлы формата ELF включают информацию для отладки, они позволяют разделить код и данные благодаря наличию отдельных секций, что позволяет предотвратить переписывание данных в этих секциях.
Позднее в процессе рассмотрения методики написания кода для работы непосредственно с аппаратным обеспечением (для нашей минималистичной операционной системы) в рамках данной серии статей мы уделим внимание и таким бинарным файлам с инструкциями центрального процессора.
Взгляд в прошлое
На данный момент в нашем распоряжении имеется файл myfirst.o с исполняемым кодом нашей программы. При этом процесс сборки программы еще не завершен; с помощью линковщика ld мы должны связать код из этого файла со специальным системным кодом запуска программ (т.е., шаблонным кодом, который исполняется при запуске каждой программы) для генерации исполняемого файла с именем myfirst. (Параметр elf_i386 описывает тип бинарного формата - в данном случае это означает, что вы можете использовать 32-битный ассемблерный код даже если вы используете 64-битный дистрибутив.)
Если процесс сборки программы пройдет успешно, вы сможете выполнить вашу программу с помощью следующей команды:
./myfirst
В результате вы должны увидеть вывод: "Assembly rules!". Это означает, что вы добились своего - создали полноценную независимую программу для Linux, код которой написан полностью на языке ассемблера. Разумеется, данная программа не выполняет каких-либо полезных действий, но при этом она является отличным примером, демонстрирующим структуру программы на языке ассемблера и позволяющим проследить процесс преобразования исходного кода в бинарный файл.
Благодаря данным системным вызовам вы можете сообщить ядру ОС о необходимости выполнения различных задач, связанных с обработкой файлов и текстовым вводом/выводом.
Перед тем, как мы перейдем к углубленному изучению кода, было бы неплохо узнать размер бинарного файла нашей программы. После выполнения команды ls -l myfirst вы увидите, что размер бинарного файла равен примерно 670 байтам. Теперь оценим размер эквивалентной программы на языке C:
#include <stdio.h>
int main()
{
puts("Assembly rules!");
}
Если вы сохраните этот код в файле с именем test.c, скомпилируете его (gcc -o test test.c) и рассмотрите параметры результирующего бинарного файла с именем test, вы обнаружите, что этот файл имеет гораздо больший размер - 8.4k. Вы можете удалить из этого файла отладочную информацию (strip -s test), но и после этого его размер сократится незначительно, лишь до 6 k. Это объясняется тем, что компилятор GCC добавляет большой объем упомянутого выше кода для запуска и завершения работы приложения, а также связывает приложение с библиотекой языка программирования C большого размера. Благодаря данному примеру несложно сделать вывод о том, что язык ассемблера является лучшим языком программирования для разработки приложений, предназначенных для эксплуатации в условиях жесткого ограничения объема носителя данных.
Следует упомянуть о том, что многие разработчики, использующие язык ассемблера, получают отличные зарплаты за разработку кода для ограниченных в плане ресурсов встраиваемых устройств и именно поэтому язык ассемблера является единственным реальным вариантом для разработки игр для старых 8-битных консолей и домашних компьютеров.
Дизассемблирование кода
Разработка нового кода является увлекательным занятием, но еще более интересным занятием может оказаться исследования чужой работы. Благодаря инструменту под названием objdump (из пакета Binutils) вы можете "дизассемблировать" исполняемый файл, а именно, преобразовать инструкции центрального процессора в их текстовые эквиваленты. Попытайтесь использовать данный инструмент по отношению к бинарному файлу myfirst, над которым мы работали в данном руководстве, следующим образом:
objdump -d -M intel myfirst
Вы увидите список инструкций из секции кода бинарного файла. Например, первая инструкция, с помощью которой мы поместили информацию о расположении нашей строки в регистр ecx, выглядит следующим образом:
mov ecx,0x80490a0
В процессе ассемблирования NASM заменил метку строки "message" на числовое значение, соответствующее расположению этой строки в секции данных бинарного файла. Таким образом, результаты дизассемблирования бинарных файлов менее полезны, чем их оригинальный код, ведь в них отсутствуют такие вещи, как комментарии и строки, но они все же могут оказаться полезными для ознакомления с реализациями критичных к времени исполнения функций или взлома систем защиты приложений. Например, в 80-х и 90-х годах многие разработчики использовали инструменты для дизассемблирования программ с целью идентификации и нейтрализации систем защиты от копирования игр.
Вы также можете дизассемблировать программы, разработанные с использованием других языков программирования, но полученные при этом результаты дизассемблирования могут быть значительно усложнены. Например, вы можете выполнить приведенную выше команду objdump по отношению к бинарному файлу /bin/ls и самостоятельно оценить тысячи строк из секции кода, сгенерированные компилятором на основе оригинального исходного кода утилиты на языке C.

Это результат дизассемблирования нашей программы, в котором представлены шестнадцатеричные коды и инструкции.
Анализ кода
А теперь давайте обсудим назначение каждой из строк кода нашей программы. Начнем с этих двух строк:
section .text global _start
Это не инструкции центрального процессора, а директивы ассемблера NASM; первая директива сообщает о том, что приведенный ниже код должен быть расположен в секции кода "text" финального исполняемого файла. Немного неочевидным является тот факт, что секция с названием "text" содержит не обычные текстовые данные (такие, как наша строка "Assembly rules!" ), а исполняемый код, т.е., инструкции центрального процессора. Далее расположена директива global _start, сообщающая линковщику ld о том, с какой точки должно начаться исполнение кода из нашего файла. Эта директива может оказаться особенно полезной в том случае, если мы захотим начинать исполнение кода не с самого начала секции кода, а из какой-либо заданной точки. Параметр global позволяет читать данную директиву не только ассемблеру, но и другим инструментам, поэтому она обрабатывается линковщиком ld.
Как было сказано выше, исполнение кода должно начинаться с позиции _start. Ввиду этого мы явно указываем соответствующую позицию в нашем коде:
_start:
Отдельные слова с символами двоеточия в конце называются метками и предназначены для указания позиций в коде, к которым мы можем перейти (подробнее об этом в следующей статье серии). Таким образом, исполнение программы начинается с этой строки! Кроме того, мы наконец достигли первой реальной инструкции центрального процессора:
mov ecx, message
Язык ассемблера является по своей сути набором мнемоник для инструкций центрального процессора (или машинного кода). В данном случае mov является одной из таких инструкций - она также может быть записана в понятном центральному процессору бинарном формате, как 10001011. Но работа с бинарными данными может превратиться в кошмар для нас, обычных людей, поэтому мы будем использовать эти более читаемые варианты. Ассемблер просто преобразует текстовые инструкции в их бинарные эквиваленты - хотя он и может выполнять дополнительную работу, о которой мы поговорим в следующих статьях серии.

А это демонстрация того, что нас ждет: код для взаимодействия с аппаратным обеспечением, исполняющийся в эмуляторе ПК! Мы также покажем вам, как загрузить его на реальной машине...
В любом случае, для того, чтобы понять назначение данной строки кода, нам также необходимо понять концепцию регистров. Центральные процессоры не выполняют каких-либо особенно сложных операций - они просто перемещают данные в памяти, используют их для осуществления вычислений и выполняют другие операции в зависимости от результатов. Центральный процессор не имеет малейшего представления о том, что такое монитор, мышь или принтер. Он просто перемещает данные и осуществляет несколько типов вычислений.
В данный момент главным хранилищем для используемых центральным процессором данных являются ваши банки оперативной памяти. Но ввиду того, что оперативная память находится за пределами центрального процессора, на осуществление доступа к ней тратится много времени. Для ускорения и упрощения описанного процесса центральный процессор содержит свою собственную небольшую группу ячеек памяти, называемую регистрами. Инструкции центрального процессора могут использовать эти регистры напрямую, причем в рассматриваемой строке кода мы используем регистр с именем ecx.
Это 32-х битный регистр (следовательно, он может хранить числа из диапазона от 0 до 4,294,967,295). При рассмотрении следующих строк кода вы увидите, что мы также работаем с регистрами edx, ebx и eax - это регистры общего назначения, которые могут использоваться для выполнения любых задач, в отличие от специализированных регистров, с которыми мы познакомимся в следующем месяце. А это небольшое пояснение для тех, кому не терпится узнать о происхождении имен регистров: регистр ecx носил имя c во время выпуска 8-ми битных процессоров, после чего был переименован в сх для хранения 16-и битных значений и в ecx для хранения 32-х битных значений. Таким образом, несмотря на то, что имена регистров в настоящее время выглядят немного странно, во времена выпуска старых центральных процессоров разработчики использовали регистры общего назначения с отличными именами a, b, c и d.
После того, как вы начнете работу, вы не сможете остановиться
Одним из вопросов, которые мы будем рассматривать в следующем месяце, является вопрос использования стека, поэтому мы подготовим вас к его рассмотрению прямо сейчас. Стек является областью памяти, в которой могут храниться временные значения тогда, когда необходимо освободить регистры для других целей. Но наиболее важной возможностью стека является способ хранения данных в нем: вы будете "помещать" ("push") значения в стек и "извлекать" ("pop") их из него. В стеке используется принцип LIFO (last in, first out - первый вошел, последний вышел), следовательно, последнее добавленное в стек значение будет первым извлечено из него.
Представьте, что у вас есть, к примеру, пустая упаковка от чипсов Pringles и вы помещаете в нее вещи в следующей последовательности: двухслойный крекер, фишка с персонажем "Альф" и диск от приставки GameCube. Если вы начнете извлекать эти вещи, вы извлечете диск от приставки GameCube первым, затем фишку с персонажем "Альф" и так далее. При работе с языком ассембера стек используется следующим образом:
push 2 push 5 push 10 pop eax pop ebx pop ecx
После исполнения этих шести инструкций регистр eax будет содержать значение 10, регистр ebx - значение 5 и регистр ecx - значение 2. Таким образом, использование стека является отличным способом временного освобождения регистров; если, к примеру, в регистрах eax и ebx имеются важные значения, но вам необходимо выполнить текущую работу перед их обработкой, вы можете поместить эти значения в стек, выполнить текущую работу и извлечь их из стека, вернувшись к предыдущему состоянию регистров.
Кроме того, стек используется при вызове подпрограмм для хранения адреса возврата к основному коду. По этой причине необходимо проявлять особую осторожность при работе со стеком - если вы перепишете хранящиеся в нем данные, вы не сможете вернуться к предыдущей позиции в основном коде приложения, отправившись в одну сторону навстречу аварийному завершению работы приложения!
Двигаемся дальше
Вернемся к коду: инструкция mov перемещает (на самом деле, копирует) число из одного места в другое, справа налево. Таким образом, в данном случае мы говорим: "следует поместить message в регистр ecx". Но что такое "message"? Это не другой регистр, это указатель на расположение данных. Ближе концу кода в секции данных "data" вы можете обнаружить метку message, после которой следует параметр db, указывающий на то, что вместо метки message в коде должно быть размещено несколько байт. Это очень удобно, так как нам не придется выяснять точное расположение строки "Assembly rules!" в секции данных - мы можем просто сослаться на нее с помощью метки message. (Число 10 после нашей строки является всего лишь символом перехода на новую строку, аналогичным символу \n, добавляемому к строкам при работе с языком программирования C).
Таким образом, мы поместили данные о расположении строки в регистр ecx. Но то, что мы сделаем дальше является особенно интересным. Как упоминалось ранее, центральный процессор не имеет какой-либо реальной концепции аппаратных устройств - для вывода чего-либо на экран вам придется отправить данные видеокарте или переместить данные в оперативную память видеокарты. Но мы не имеем какой-либо информации о расположении этой оперативной памяти видеокарты, кроме того, все используют различные видеокарты, параметры сервера оконной системы X, оконные менеджеры и.т.д. Исходя из этого, непосредственный вывод чего-либо на экран с помощью небольшой по объему программы в нашем случае практически невозможен.
Поэтому мы попросим ядро ОС сделать это для нас. Ядро Linux предоставляет в распоряжение низкоуровневых приложений большое количество системных вызовов, с помощью которых приложения могут инициировать выполнение различных операций на уровне ядра. Один из этих системных вызовов предназначен для вывода текстовой строки. После использования этого системного вызова ядро ОС выполняет всю необходимую работу - и, разумеется, оно предоставляет даже более глубокий уровень абстракции, на котором строка может быть выведена с помощью обычного текстового терминала, эмулятора терминала оконной системы X или даже записана в открытый ранее файл.
Однако, перед тем, как сообщить ядру ОС о необходимости вывода текстовой строки, нам придется передать ему дополнительную информацию, помимо информации о расположении строки, уже находящейся в регистре ecx. Также нам придется сообщить ему о том, сколько символов нужно вывести для того, чтобы вывод строки не продолжался после ее окончания. Именно для этого используется строка из секции данных ближе к концу кода приложения:
length equ $ - message
В данной строке используется другая метка length, но вместо параметра db для связывания этой метки с какими-либо данными, мы используем параметр equ для того, чтобы сообщить, что данная метка является эквивалентом чего-либо (это немного похоже на директиву препроцессора #define в языке программирования C). Символ доллара соответствует текущей позиции в коде, поэтому в данном случае мы говорим: "метка length должна быть эквивалентна текущей позиции в коде за вычетом расположения строки с меткой "message"".
Вернемся к секции кода приложения, в которой мы размещаем данное значение в регистре edx:
mov edx, length
Все идет отлично: два регистра заполнены информацией о расположении строки и количестве символов строки для вывода. Но перед тем, как мы сообщим ядру ОС о необходимости выполнения его части работы, нам придется предоставить ему еще немного информации. Во-первых, мы должны сообщить ядру ОС о том, какой "дескриптор файла" следует использовать - другими словами, куда должен быть направлен вывод. Данная тема выходит за границы руководства по использованию языка ассемблера, поэтому скажем лишь, что нам нужно использовать стандартный поток вывода stdout, что означает: выводить строку на экран. Стандартный поток вывода использует фиксированный дескриптор 1, который мы помещаем в регистр ebx.
Теперь мы крайне близки к осуществлению системного вызова, но остался еще один регистр, который должен быть заполнен. Ядро ОС может выполнять большое количество различных операций, таких, как монтирование файловых систем, чтение данных из файлов, удаление файлов и других. Соответствующие механизмы активируются с помощью упомянутых системных вызовов и перед тем, как мы передадим управление ядру ОС, нам придется сообщить ему, какой из системных вызовов следует использовать. На странице http://asm.sourceforge.net/syscall.html вы можете ознакомиться с информацией о некоторых системных вызовах, доступных программам - в нашем случае необходим системный вызов sys_write ("запись данных в дескриптор файла") с номером 4. Поэтому мы разместим его номер в регистре eax:
mov eax, 4
И это все! Мы выполнили все необходимые приготовления для осуществления системного вызова, поэтому сейчас мы просто передадим управление ядру ОС следующим образом:
int 0x80
Инструкция int расшифровывается как "interrrupt" ("прерывание") и буквально прерывает поток исполнения данной программы, переходя в пространство ядра ОС. (В данном случае используется шестнадцатеричное значение 0x80 - пока вам не следует беспокоиться о нем.) Ядро ОС осуществит вывод строки, на которую указывает значение в регистре ecx, после чего вернет управление нашей программе.
Для завершения исполнения программы следует осуществить системный вызов sys_exit, который имеет номер 1. Поэтому мы размещаем данный номер в регистре eax, снова прерываем исполнение нашей программы, после чего ядро ОС аккуратно завершает исполнение нашей программы и мы возвращаемся к приветствию командной оболочки. Можно сказать, что вы выполнили поставленную задачу: реализовали завершенную (хотя и очень простую) программу на языке ассемблера, код которой разработан вручную без использования каких-либо объемных библиотек.
Мы рассмотрели достаточно много аспектов использования языка ассемблера в данном руководстве и, как упоминалось ранее, вместо этого мы могли бы сфокусироваться лишь на теоретической информации. Но я все же надеюсь, что реальный пример программы оказался полезным для вас, а в следующем номере журнала мы потратим больше времени на рассмотрение некоторых концепций, которые были затронуты в данном руководстве. Кроме того, мы усовершенствуем нашу программу, добавив в нее логику и подпрограммы - версии операторов if и goto языка ассемблера.
В процессе ознакомления с кодом данной программы вы можете попытаться самостоятельно модифицировать его для выполнения следующих операций:
- Вывода отличной, более длинной строки.
- Вывода двух строк, одна после другой.
- Возврата измененного кода завершения работы приложения командной оболочке (для этого придется воспользоваться поисковой системой Google!).
Если вы столкнулись с трудностями и нуждаетесь в помощи, заходите на наш форум по адресу http://forums.linuxvoice.com - автор руководства будет рядом и с удовольствием направит вас по правильному пути. Удачного программирования!