Библиотека сайта rus-linux.net
Ошибка базы данных: Table 'a111530_forumnew.rlf1_users' doesn't exist
dd: Команда, которая не похожа на другие
Автор: Алексей ДмитриевДата: ноябрь 2008
Немного истории
Команда dd практически ровесник ОС Юникс. Днем рождения последней считается 1 января 1970, и точно известно, что уже в 1970 году утилита dd работала с ленточными накопителями, при помощи которых данные переносили с одной ЭВМ на другую, а также запускали и устанавливали ОС Юникс на популярные тогда мини-ЭВМ PDP/11.

Рисунок 1. Мини-ЭВМ PDP/11
Расшифровка названия команды тоже относится к этим давно ушедшим временам. В языке IBM System/360 JCL был оператор DD 'Dataset Definition' (Определение набора данных), имя которого и получила вновь созданная команда.

Рисунок 2. Перфолента PDP/11
Расшифровок приходилось встречать много, в частности в рунете популярна расшифровка Disk Dump (не то разгрузка, не то загрузка диска) - версия слабая, так как в описываемые времена ни дисков, ни дампов (что бы под ними не понимали) еще не было. Гораздо ближе к сути команды шутливые расшифровки: "data destroyer" или "delete data", что можно перевести как "Доконай Диск" или "Добей Данные", потому что при неправильном использовании команды раздел или выходной файл мгновенно превращаются в хлам. Поскольку dd является инструментом для создания головных меток диска, загрузочных записей и тому подобных системных областей диска, наверняка многие жесткие диски и файловые системы были уничтожены неправильным применением dd.
Синтаксис, не похожий на команду Юникс
Из глубины времен пришел и синтаксис команды dd, не похожий ни на одну команду Юникс. Синтаксис команды dd кардинально отличается от синтаксиса большинства остальных команд Юникс. Благодаря своей уникальности он устоял против недавних попыток унифицировать синтаксис для всех программ командной строки. Так dd использует формат 'опция=значение', в то время как большинство команд Юникс используют формат ' -опция значение'. Кроме того, ввод команды dd определяется опцией "if" (input file), в то время как большинство команд просто используют само имя, без всяких опций. Существует мнение, что такой синтаксис основан на языке программирования IBM System/360 JCL, также ходят слухи, что этот синтаксис был создан как шутка; тем не менее, не было ни одной попытки написать замену программе dd, которая более походила бы на команду Юникс.Даже говоря о формате синтаксиса dd 'опция=значение', я допускаю неточность. Опций в прямом смысле у этой команды всего две: --help и --version, их применение очевидно. Все остальные элементы синтаксиса называются операндами. Их не так уж и много, но многие столь сложно зависят друг от друга, что, если начать приводить их по списку, то получится очередной ман, разобраться в котором не просто. (Мне встречались даже маны с внутренними ссылками, но сильно это не помогало).
Поэтому в этой статье я делаю упор на примеры (не торопитесь щелкать по ссылкам, вы доберетесь до примеров, читая статью последовательно).
Список примеров
Пример 1. Простое копирование.
Пример 2. Создание загрузочной дискеты из файла-образа.
Пример 3. Разрезать 10 мегабайтный файл на два пяти-мегабайтных
Пример 4. Вывести на экран первые 100 байт содержимого файла
Пример 5. Создание образа оптического диска
Пример 6. Ускорениe работы некоторых Live CD
Пример 7. Увеличить размер существующего файла до 1Гб без перезаписи
Пример 8. Создание загрузочной дискеты Grub
Пример 9. Создание загрузочного образа
Пример 10. Вывести на экран MBR
Пример 12. Преобразование верхнего регистра в нижний
Пример 13. Создание резервной копии жесткого диска
Пример 14. Создание резервного образа жесткого диска
Пример 15. Уничтожение всех данных в разделе
Для знакомства с большинством обычных действий с командой dd нужно начать с нескольких простых операндов.
Обычные варианты применения команды dd
Начнем знакомство с операндами команды dd:if=filename (input file) Этот операнд задает входной файл; если он не указан, то по умолчанию используется стандартный ввод. Этим файлом может быть также файл (нода) устройства, например /dev/hda1, или специфические файлы типа /dev/zero.
of=filename (output file) Задает выходной файл; если он не указан, то по умолчанию используется стандартный вывод (экран монитора).
Знакомство с этими двумя операндами уже дает нам возможность использовать программу dd для копирования файлов.
Пример 1. Простое копирование.
# dd if=/home/ya/Desktop/shema.txt of=/home/ya/Desktop/shema.html
3+1 записей считано
3+1 записей написано
скопировано 1549 байт (1,5 kB), 0,427457 секунд, 3,6 kB/s
Как мы видим, программа dd сняла копию файла shema.txt и записала данные в файл shema.html. При этом она выдала нам сообщение.
Разберемся, о чем говорится в этом сообщении. Команда dd считывает и записывает блоками по N байт в каждом. Поскольку мы не задали в командной строке размер блока, то программа использовала размер блока по умолчанию, равный 512 байт. Всего скопировано 1549 байт, как записано в последней строке сообщения. "3+1 записей считано" означает число полных блоков - 3 плюс один неполный блок, содержащий оставшиеся байты 1549-(3*512)=13. То же относится и к строке "3+1 записей написано".
Теперь самое время разобраться с размером блока.
Сразу скажу, что блок команды dd не имеет никакого отношения к блокам данных файловой системы. Программа dd работает с необработанными "сырыми" (raw data) данными на низком уровне, т.е. на уровне секторов жесткого диска. А любая файловая система является надстройкой над этим уровнем. Правильнее было бы назвать блок буфером. Мы имеем два буфера - входной буфер и выходной буфер. Величина буфера задается операндом bs (block size) и исчисляется в байтах. Например, запись bs=512 означает, что нами установлен размер блока (буфера) в 512 байт. Кстати это значение и используется по умолчанию. Если величина блока не указана, dd использует блоки по 512 байт, что подходит для абсолютного большинства задач. Итак, величина буфера задана, dd создает 512-байтный буфер считывания, посылает единственный запрос на чтение со входного файла, затем создает 512-байтный буфер записи и посылает единственный запрос на запись в выходной файл. Давайте сравним работу программы dd и программы cp при копировании дискеты.
# dd if=/dev/fd0 of=floppy.img bs=1474560
1+0 записей считано
1+0 записей написано
скопировано 1474560 байт (1,5 MB), 0,0438156 секунд, 33,7 MB/s
Может возникнуть вопрос: "А почему именно 1474560 байт, а не 1440 000, как принято считать размер дискеты?" Это значение складывается из: 2 головки, 80 цилиндров, 18 секторов/дорожку при длине сектора 512 байт. Итого: 2*80*18*512=1474560 байт.
Команде же
# cp /dev/fd0 floppy.img
требуется послать 360 запросов по 4096 байт (размер блока данных), что даст те же 360*4096=147560 байт. Для файла размером 1.44Mб это может показаться незначительным, но когда производятся операции с большими объемами данных, уменьшение числа системных вызовов приводит к существенному повышению быстродействия системы.
Итак, размер блока задается операндом
bs=n(байт)
Существуют и другие способы задания этого параметра, например при помощи знака <х>, который понимается как умножение. Только что мы вычисляли точный размер дискеты, тем же способом можно задать величину блока:
bs=2х80х18х512
или используя суффиксы:
bs=2x80x18b
где суффикс b означает 512, а вся запись аналогична предыдущей. Применяются следующие суффиксы:
w означает 2 (в некоторых реализациях 4) b означает 512 k означает 1024
Короче говоря, как часто бывает в Юниксе, все максимально запутано и требует недюжинной памяти. Но и это еще не все. Кроме bs, существуют еще три операнда размера блока:
ibs=n(байт) Этот операнд определяет размер входного блока. Правила его задания такие же, как для bs.
obs=n(байт) Этот операнд определяет размер выходного блока. Правила его задания такие же, как для bs.
bs является как бы старшим операндом, и если он задан, то ibs и obs игнорируются. ibs и obs нужны в тех случаях, когда необходимо задать различные значения входного и выходного блоков.
И четвертый операнд, связанный с размером блока:
cbs=n(байт) Определяет размер буфера (блока) преобразования. О нем мы будем говорить в главе, посвященной преобразованиям форматов данных.
Теперь, когда мы умеем задавать размеры блока, мы можем выполнить очень важную задачу - снять резервную копию Главной загрузочной записи - MBR. Все, у кого на компьютере имеется несколько операционных систем, должны иметь такую копию, и обновлять ее при каждом изменении системы. MBR находится в 0 секторе первого раздела жесткого диска и занимает вместе с таблицей разделов ровно 512 байт.
Для того чтобы скопировать MBR, следует познакомиться с еще одним операндом:
count=n(блоков) Этот операнд определяет количество блоков, подлежащих копированию. Например запись
bs=512 count=100
означает приказ скопировать 100 блоков по 512 байт каждый. Здесь также возможно применение суффиксов, например
bs=512 count=1k
означает, что будет скопировано 1024 блока по 512 байт каждый.
Внимание! Операнд count имеет дело с блоками, а не с байтами!
Команда, которая скопирует нам MBR в файл backup.mbr выглядит так:
# dd if=/dev/hda of=backup.mbr bs=512 count=1
1+0 записей считано
1+0 записей написано
скопировано 512 байт (512 B), 0,000358146 секунд, 1,4 MB/s
Резервная копия создана, теперь главное не забыть, где она лежит. И если какой-нибудь вредный дистрибутив криво установит нам загрузчик Grub, то мы спокойно проделаем обратную операцию:
# dd if=backup.mbr of=/dev/hda bs=512 count=1
И машина снова станет загружаться. Просмотреть полученную копию можно в любом двоичном (шестнадцатеричном) редакторе, например Khexedit или редакторе из Midnight Commander.
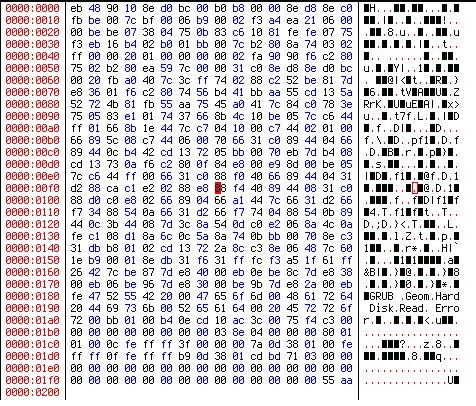
Рисунок 3. MBR полностью, все 512 байт
А если нам нужно не весь MBR, а только загрузочный код, который занимает первые 446 байт 0 сектора? Тогда придется изменить размер блока:
# dd if=/dev/hda of=boot-code.mbr bs=446 count=1
1+0 записей считано
1+0 записей написано
скопировано 446 байт (446 B), 0,0345156 секунд, 1,4 MB/s
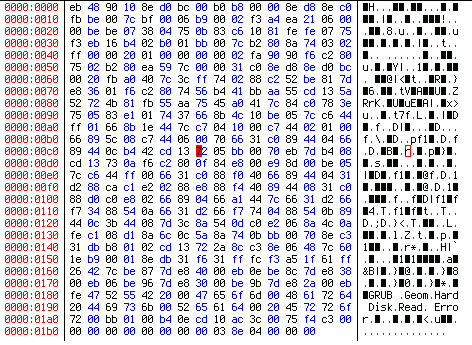
Рисунок 4. Загрузочная программа, занимающая первые 446 байт MBR
Если же мы хотим сохранить только таблицу разделов, а загрузочный код (скажем от Windows) нам больше не нужен? Для выполнения этой задачи нам нужно познакомиться еще с одним операндом:
skip=n(блоков) Этот операнд пропускает n блоков от начала входного (if) файла, а затем копирует указанное количество блоков.
Внимание! Операнд skip (как и count) имеет дело с блоками, а не с байтами! Поэтому размер блока следует выбирать вдумчиво. Что мы и сделаем:
# dd if=/dev/hda of=part-table.mbr bs=1 count=66 skip=446
66+0 записей считано
66+0 записей написано
скопировано 66 байт (66 B), 0,034515 секунд, 11,9 kB/s
Мы выбрали размер блока в 1 байт, и бесхитростно указываем нужные параметры в байтах.
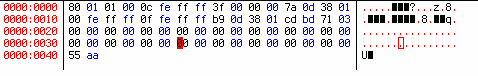
Рисунок 5. Таблица разделов вместе с сигнатурой (55 аа)
Может возникнуть вопрос: "Почему копировали 66 байт, хотя известно, что таблица разделов занимает 16*4=64 байта?" Дело в том, что последние два байта в таблице разделов занимает так называемая сигнатура (подпись) [55 аа], без которой ни один компьютер не опознает таблицу разделов. И поскольку мы делаем резервную копию, то, во избежание забывчивости и недоразумений при будущем восстановлении таблицы разделов, присоединили сигнатуру к таблице разделов.
Как вам нравится рисунок 5? Какой-то он непривычный (смещение на два байта) и неинформативный. Лучше бы иметь стандартную распечатку MBR, в котором первые 446 байт заменены, скажем, нулями. Если придется править вручную, будет намного удобнее. Команда dd позволяет и это. Только нужно применить еще один операнд:
seek=n(блоков) Этот операнд пропускает в выходном файле (of) n блоков, прежде чем начать туда запись.
Внимание! Операнд seek (как и skip и count) имеет дело с блоками, а не с байтами!
Место пропущенных блоков он заполняет нулями. Значит нам нужно применить такую команду:
# dd if=/dev/hda of=part-table.mbr bs=1 count=66 skip=446 seek=446
66+0 записей считано
66+0 записей написано
скопировано 66 байт (66 B), 0,034515 секунд, 12,9 kB/s
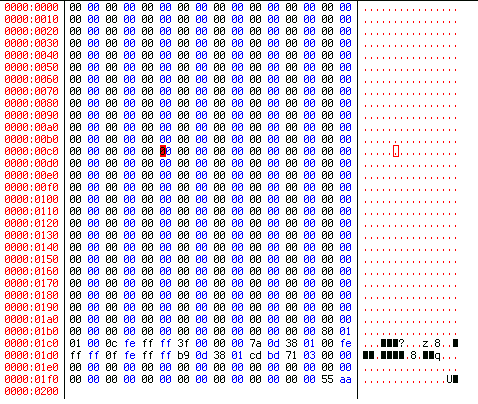
Рисунок 6. Теперь таблица разделов приобрела привычный, удобопонятный вид. И сигнатура на месте.
| К началу. | Вперед, страницы 2, 3, 4. |