Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти
Часть 5. Что могут делать программисты - оптимизация кеша
Оригинал: What every programmer should know about memory. Memory part 5: What programmers can do.Автор: Ulrich Drepper
Дата публикации: 23.10.2007
Перевод: Капустин С.В.
Дата перевода: 30.10.2009
6. Что могут делать программисты?
Исходя из изложенного в предыдущих главах ясно, что существует много, очень много возможностей для программиста влиять на производительность программы, позитивно или негативно. И это только для операций, связанных с использованием памяти. Мы будем описывать эти возможности снизу вверх - начнем с нижних уровней физического доступа к памяти и кэшу L1 и закончим функциональностью операционной системы, которая влияет на работу с памятью.
6.1 Обход кэша
Когда данные произведены и не (сразу) используются снова, тот факт, что операции сохранения в памяти требуют сначала чтения полной строки кэша, затем модификации кэшированных данных, отрицательно сказывается на производительности. Эта операция выталкивает из кэшей данные, которые могут понадобится снова, заменяя их на данные, которые не скоро понадобятся. Это особенно верно для больших структур данных, таких как матрицы, которые заполняются и затем используются позднее. Прежде чем заполнен последний элемент матрицы, из-за большого размера первые элементы выталкиваются, делая кэширование записи неэффективным.
Для этой и подобных ситуаций процессоры поддерживают запись данных методом "не промежуточного" (non-temporal) сохранения. "Не промежуточное" в этом контексте означает, что данные будут использоваться не скоро, поэтому нет смысла их кэшировать. Это "не промежуточное" сохранение не читает строку из кэша и не меняет её, вместо этого новые данные сохраняются непосредственно в память.
Это может показаться весьма затратным процессом, но это не обязательно так. Процессор попытается использовать политику записи write-combining (см. 3.3.3), чтобы заполнить целую строку кэша. Если это удастся, не нужно будет никаких операций чтения. Для архитектур x86 и x86-64 gcc предоставляет несколько встроенных функций компилятора:
#include <emmintrin.h> void _mm_stream_si32(int *p, int a); void _mm_stream_si128(int *p, __m128i a); void _mm_stream_pd(double *p, __m128d a); #include <xmmintrin.h> void _mm_stream_pi(__m64 *p, __m64 a); void _mm_stream_ps(float *p, __m128 a); #include <ammintrin.h> void _mm_stream_sd(double *p, __m128d a); void _mm_stream_ss(float *p, __m128 a);
Эти инструкции работают наиболее эффективно, если они обрабатывают большие объемы данных за один раз. Данные загружаются из памяти, обрабатываются за один или более шагов, и затем записываются обратно в память. Данные идут "потоком" через процессор, отсюда и название функций.
Адреса памяти должны быть выравнены по 8 или 16 бит соответственно. В коде, использующем
мультимедийные расширения, можно заменять обычные встроенные функции _mm_store_* этими "не промежуточными" версиями. В программе перемножения матриц в разделе 9.1 мы не делаем этого, так как записанные значения вскоре снова будут использованы. Это пример, когда потоковые инструкции не подходят. Подробнее об этой программе в разделе 6.2.1.
Буфер процессора, используемый для write-combining, может хранить запросы на частичную запись в строку кэша только небольшое время. В общем необходимо использовать инструкции, модифицирующие одну строку кэша, одну следом за другой, чтобы метод write-combining мог действительно работать. Вот пример того, как это делать:
#include <emmintrin.h>
void setbytes(char *p, int c)
{
__m128i i = _mm_set_epi8(c, c, c, c,
c, c, c, c,
c, c, c, c,
c, c, c, c);
_mm_stream_si128((__m128i *)&p[0], i);
_mm_stream_si128((__m128i *)&p[16], i);
_mm_stream_si128((__m128i *)&p[32], i);
_mm_stream_si128((__m128i *)&p[48], i);
}
Предполагая, что указатель p подходящим образом выравнен, вызов этой функции устанавит
все байты адресуемой строки кэша равными c. Логика, управляющая write-combining, увидит
четыре сгенерированные инструкции movntdq и выполнит команду на запись в память только
когда последняя инструкция будет выполнена. Суммируя: эта последовательность кода позволит избежать
не только чтения строки кэша перед записью, но и засорения кэша данными, которые могут не скоро
понадобиться. Это может принести огромную пользу в определенных ситуациях. Примером обычного кода, использующего эту технику может служить функция memset из библиотеки C, которая должна использовать такую же последовательность кода для больших блоков.
Некоторые архитектуры предлагают специализированные решения. Архитектура PowerPC определяет инструкцию dcbz, которая может быть использована, чтобы очистить целую строку кэша. Эта инструкция не обходит кэш, так как для результата выделяется строка кэша, но данные из памяти не читаются. Она более ограничена, чем инструкции "не промежуточного" сохранения, так как строка кэша может быть заполнена только нулями и это загрязняет кэш (если данные не должны вскоре использоваться), но для неё не требуется логики write-combining.
Чтобы увидеть эти "не промежуточные" инструкции в действии, мы рассмотрим новый тест, измеряющий запись в матрицу, организаванную как двумерный массив. Компилятор располагает матрицу в памяти так, что левый (первый) индекс адресует строку, элементы которой располагаются в памяти последовательно. Правый (второй) индекс адресует элементы строки. Тестовая программа проходит матрицу двумя путями: сначала во внутреннем цикле увеличивается номер колонки, потом во внутреннем цикле увеличивается номер строки. Это означает, что мы имеем процесс как на рисунке 6.1.
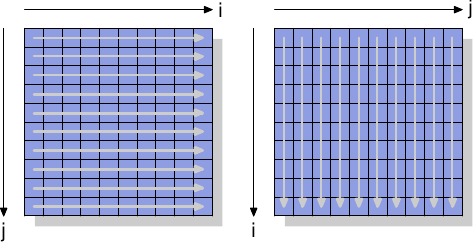
Рисунок 6.1: Образцы доступа к матрице
Мы измеряем сколько потребуется времени для того чтобы инициализировать матрицу размером 3000×3000. Чтобы увидеть как ведет себя память, мы используем инструкции сохранения, которые не используют кэш. На процессорах архитектуры IA-32 для этого используется индикатор ⌠non-temporal hint■. Для сравнения мы измеряем также обычные операции сохранения. Результаты приведены в таблице 6.1.
Приращение внутреннего цикла Строка Колонка Обычная 0.048с 0.127с Не промежуточная 0.048с 0.160с Table 6.1: Инициализация матрицы
Для обычной записи, которая использует кэш, мы видим ожидаемый результат: если память используется последовательно, мы имеем гораздо лучший результат, 0.048с на всю операцию, что составляет примерно 750Мб/с, в сравнении с более или менее случайным доступом который занимает 0.127с (около 280Мб/с). Матрица достаточно велика, чтобы сделать кэш неэффективным.
Нас здесь больше интересует запись, делаемая в обход кэша. Может показаться удивительным, что последовательный доступ здесь такой же быстрый как в случае использования кэша. Причина этого в том, что процессор использует политику записи write-combining как объяснялось выше. К тому же правила упорядочивания памяти для "не промежуточной" записи ослаблены: программа должна явным образом указывать барьеры памяти (инструкция sfence для процессоров x86 и x86-64). Это означает, что процессор имеет больше свободы при записи данных и использует доступную пропускную способность наиболее эффективно.
В случае доступа по колонкам во внутреннем цикле ситуация другая. Результат значительно медленнее, чем при использовании кэша (0.16с, около 225Мб/с). Здесь мы видим, что write combining невозможно и каждая ячейка памяти адресуется индивидуально. Это требует постоянного выбора новых строк в чипе RAM с сопутствующими этому задержками. Результат на 25% хуже, чем при использовании кэша.
В отношении чтения, процессорам до недавних пор недоставало поддержки, если не считать слабых индикаторов, использующих инструкции предварительной выборки "не промежуточного" доступа (NTA, non-temporal access). Для чтения нет эквивалента политике write-combining, что особенно плохо для некэшируемой памяти, такой как отображаемый в память ввод/вывод. Intel в расширениях SSE4.1 вводит загрузки NTA. Они реализованы с использованием небольшого количества потоковых буферов загрузки, каждый буфер содержит строку кэша. Первая инструкция movntdqa для заданной строки кэша загружает строку кэша (т.е. строку, которая могла бы быть загружена в кэш) в буфер, возможно замещая там другую строку. Последующие обращения, выравненные по 16 байт, к этой строке будут обслуживаться буфером с небольшими затратами. Если для этого не будет других причин, то строка кэша не будет загружена в кэш, что позволит загружать большие объемы памяти, не загрязняя кэш. Компилятор предоставляет встроенную функцию для этой инструкции
#include <smmintrin.h> __m128i _mm_stream_load_si128 (__m128i *p);
Эта встроенная функция должна быть использована много раз с адресами 16-байтовых блоков, передаваемых в качестве параметра, пока не прочитаны все строки кэша. Только тогда можно начинать следующую строку кэша. Так как буферов чтения несколько, возможно чтение из двух мест в памяти одновременно.
Из этого эксперимента мы должны вынести то, что современные процессоры очень хорошо оптимизируют некэшированный доступ на запись и (с недавних пор) на чтение, при условии что этот доступ последовательный. Это знание может быть очень полезно при работе с большими структурами данных, которые используются только один раз. Второе - кэши могут помочь покрыть некоторые, хотя и не все, затраты на произвольный доступ к памяти. Произвольный доступ в этом примере на 70% медленнее из-за особенностей устройства доступа к RAM. Пока эти устройства не поменяются, произвольного доступа следует по возможности избегать.
В разделе, посвященном предварительной выборке мы еще рассмотрим "не промежуточный" флаг.
6.2 Доступ к кэшу
Наиболее важные улучшения, которые программист может внести в работу с кэшами, относятся к кэшу уровня 1. Мы обсудим их первыми, до работы с другими уровнями. Очевидно, что оптимизация кэша уровня 1 повлияет и на другие кэши. Тема для любого доступа к памяти одна - улучшайте локальность (пространственную и временную) и выравнивайте код и данные.
6.2.1 Оптимизация доступа к кэшу данных 1 уровня
В разделе 3.3 мы уже видели насколько эффективное использование кэша L1d может повысить производительность. В этом разделе мы покажем, какие изменения в коде могут помочь её улучшить. В продолжение предыдушего раздела, мы сначала сконцентрируемся на оптимизации, которая позволит сделать доступ к памяти последовательным. Числа в разделе 3.3 показывают, что процессор автоматически делает предварительную выборку данных при последовательном доступе к памяти.
Для примера используется код перемножения матриц. Мы используем две квадратные матрицы размера 1000×1000. Для тех, кто забыл математику, произведение двух матриц A и B с элементами aij и bij, где 0 ≤ i,j < N, это матрица с элементами
![[formula]](/MyLDP/hard/memory/5/matrixmult.png)
Прямое использование этой формулы в программе на C может выглядеть так:
for (i = 0; i < N; ++i)
for (j = 0; j < N; ++j)
for (k = 0; k < N; ++k)
res[i][j] += mul1[i][k] * mul2[k][j];
Две исходные матрицы это mul1 и mul2. Матрица результата res изначально инициализирована нулями. Милая и простая реализация. Но должно быть очевидным, что мы имеем в точности ту же проблему, как на рисунке 6.1. Доступ к mul1 последовательный, а для mul2 внутренний цикл увеличивает номер строки. Это означает, что работа с mul1 идет как с левой матрицей на рисунке 6.1, а работа с mul2 идет как с правой матрицей. Это нехорошо.
Есть возможное решение, которое легко попробовать. Так как каждый элемент матрицы используется много раз, может стоит преобразовать ("транспонировать", говоря математическим языком) вторую матрицу mul2, перед тем как использовать её.
![[formula]](/MyLDP/hard/memory/5/matrixmultT.png)
После транспозиции (традиционно обозначаемой верхним индексом ‘T’) мы обходим обе матрицы последовательно. В коде C это будет выглядеть так:
double tmp[N][N];
for (i = 0; i < N; ++i)
for (j = 0; j < N; ++j)
tmp[i][j] = mul2[j][i];
for (i = 0; i < N; ++i)
for (j = 0; j < N; ++j)
for (k = 0; k < N; ++k)
res[i][j] += mul1[i][k] * tmp[j][k];
Мы создаем временную переменную, которая будет содержать транспонированную матрицу. Это потребует выделения большего количества памяти, но затраты, можно надеяться, окупятся, так как 1000 не последовательных обращений на колонку обойдутся дороже (по крайней мере на современном оборудовании). Пора сделать какой-нибудь тест производительности. Результат на Intel Core 2 с тактовой частотой 2666МГц (в циклах процессора):
Исходная Транспонированная Циклы 16,765,297,870 3,922,373,010 Относительно 100% 23.4%
Простая трансформация матрицы дает выигрыш в 76.7%! Операция копирования более чем окупилась. 1000 не последовательных обращений к памяти - действительно проблема.
Следующий вопрос - наилучшее ли это решение? Мы определенно нуждаемся в альтернативном методе, который не требует дополнительного копирования. Не всегда можно позволить себе такую роскошь как копирование - матрица может быть слишком большой или доступная память слишком маленькой.
Поиск альтернативного метода нужно начать с пристального изучения используемой математики и операций, выполняемых в исходном решении. Тривиальные математические правила говорят, что порядок, в котором происходит суммирование для каждого элемента матрицы результата, не имеет значения, каждое слагаемое появляется только раз (мы игнорируем здесь арифметические эффекты, которые могут вызвать появление переполнения, потери значимости, округления). Это понимание позволяет нам искать решения, связанные с переупорядочиванием сложения, выполняемого во внутреннем цикле исходного кода.
Давайте посмотрим, в чем состоит проблема при исполнении исходного кода. Порядок, с которым происходит обращение к элементам mul2 такой: (0,0), (1,0), …, (N-1,0), (0,1), (1,1), …. Элементы (0,0) и (1,0) находятся в одной строке кэша, но пока внутренний цикл будет пройден один раз, эта строка давно уже будет исключена из кэша. Для этого примера каждый проход внутреннего цикла требует для каждой из трех матриц 1000 строк кэша (размером 64 байта для процессора Core 2). Это гораздо больше, чем 32Кб кэша L1d.
Но что, если мы будем обрабатывать две итерации среднего цикла вместе при прохождении внутреннего цикла? В этом случае мы используем два значения double из строки кэша, которые гарантированно будут в L1d. Мы сократим показатель промахов в L1d наполовину. Это определенно улучшение, но, в зависимости от размера строки кэша, это все еще может быть не наилучшим решением. Процессор Core 2 имеер размер строки кэша L1d 64 байта. Это значение можно выяснить используя
sysconf (_SC_LEVEL1_DCACHE_LINESIZE)
во время выполнения, или используя getconf в командной строке, так что программу можно скомпилировать для специфического размера строки кэша. При sizeof(double) равном 8 это означает, что для того, чтобы полностью использовать строку кэша, мы должны делать 8 итераций среднего цикла за один раз. Продолжая эту мысль, чтобы эффективно использовать также и матрицу res, т.е. чтобы записывать 8 результатов одновременно, мы должны делать также и 8 итераций внешнего цикла за один раз. Мы предполагаем здесь размер строки кэша 64, но код будет работать так же хорошо на системах с 32-байтными строками кэша, так как обе строки кэша будут использованы на 100%. В общем случае лучше всего зафиксировать размер строки кэша во время компиляции, используя утилиту getconf:
gcc -DCLS=$(getconf LEVEL1_DCACHE_LINESIZE) ...
Если бинарник предполагается к распространению, то нужно использовать наибольший размер строки кэша. Для очень маленького L1d это может означать, что не все данные попадут в кэш, но такие процессоры все равно не подходят для высокопроизводительных программ. Код, к которому мы приходим, должен выглядеть примерно так:
#define SM (CLS / sizeof (double))
for (i = 0; i < N; i += SM)
for (j = 0; j < N; j += SM)
for (k = 0; k < N; k += SM)
for (i2 = 0, rres = &res[i][j],
rmul1 = &mul1[i][k]; i2 < SM;
++i2, rres += N, rmul1 += N)
for (k2 = 0, rmul2 = &mul2[k][j];
k2 < SM; ++k2, rmul2 += N)
for (j2 = 0; j2 < SM; ++j2)
rres[j2] += rmul1[k2] * rmul2[j2];
Выглядит устрашающе. Это потому, что код содержит некоторые трюки. Самое заметное изменение состоит в том, что мы имеем 6 вложенных циклов. Внешние циклы имеют приращение SM (размер строки кэша, деленный на sizeof(double)). Это разделяет умножение на несколько более мелких задач, которые могут быть решены с большей локальностью кэша. Внутренние циклы выполняют итерации для индексов, пропущенных во внешних циклах. Получается снова три цикла. Единственный трюк здесь в том, что циклы для k2 и j2 идут в другом порядке. Это сделано потому, что при вычислении только одно выражение зависит от k2, а от j2 зависят два.
Остальные сложности являются результатом того, что компилятор gcc недостаточно умен, когда речь
идет об оптимизации индексов массива. Введение дополнительных переменных rres,
rmul1 и rmul2 оптимизирует код, вытягивая обычные выражения из внутренних
циклов настолько далеко, насколько это возможно. Правила по умолчанию для псевдонимов в языках C
и C++ не могут помочь компилятору сделать эти решения (если не используется ключевое слово
restrict, то любой доступ через указатели является потенциальным источником появления
псевдонимов). Вот почему Fortran все еще является предпочтительным языком для численного
программирования - он позволяет легче писать быстрый код. {В теории, ключевое слово
restrict, введенное в язык С в ревизии 1999 года, должно решить эту проблему. Компиляторы, однако, пока этого не поддерживают. Причина, в основном, в том, что существует очень много некорректного кода, который бы ввел компилятор в заблуждение и заставил его генерировать некорректный объектный код.}
В таблице 6.2 мы видим как вся эта работа окупается.
| Исходная | Транспонированная | Подматрицы | Векторизированно | |
|---|---|---|---|---|
| Циклы | 16,765,297,870 | 3,922,373,010 | 2,895,041,480 | 1,588,711,750 |
| Относительно | 100% | 23.4% | 17.3% | 9.47% |
Таблица 6.2: Замеры времени умножения матриц
Исключая копирование, мы получаем еще 6.1% производительности. Плюс нам не нужна дополнительная память. Входящие матрицы могут быть сколько угодно большими, пока матрица результата помещается в памяти. Это требование общего решения, которого мы теперь достигли.
В таблице 6.2 есть одна колонка, которую мы еще не объяснили. Большинство современных процессоров имеют сегодня поддержку векторизации. Часто подаваемые как мультимедийные расширения, эти специальные инструкции позволяют обрабатывать 2,4,8 или более значений одновременно. Часто это операции SIMD (Single Instruction, Multiple Data - одна инструкция много данных), дополненные другими, для приведения данных в нужную форму. Инструкции SSE2, которые поддерживают процессоры Intel, могут обрабатывать два двойных слова за одну операцию. Справочное руководство содержит список встроенных функций компилятора, которые предоставляют доступ к этим инструкциям SSE2. Если используются эти функции, программа работает еще на 7.3% быстрее, по сравнению с оригиналом. В результате мы получаем программу, которая делает работу за 10% времени работы исходного кода. Переведя в цифры, понятные для людей мы перешли от 318 мегафлоп к 3.35 гигафлоп. Так как мы интересуемся здесь только эффектами в памяти, код программы помещен в раздел 9.1.
Следует отметить, что в последней версии кода мы все еще имеем проблемы кэширования mul2 - предварительная загрузка так и не работает. Это нельзя решить без транспонирования матрицы. Может быть модули предварительной загрузки кэша станут умнее и смогут узнавать такую ситуацию, тогда дополнительных изменений не потребуется. 3.19 гигафлоп на процессоре 2.66ГГц с одноядерным кодом все равно неплохо.
В этом примере с произведением матриц мы оптимизировали использование загруженных строк кэша. Все байты строки кэша всегда используются. Мы просто делаем так, что они используются до того, как строка кэша исключена. Это определенно частный случай.
Более распространена ситуация, когда мы имеем структуры данных, которые заполняют одну или более строк кэша, хотя программа испольует всего несколько членов такой структуры данных за раз. На рисунке 3.11 мы уже видели эффекты большого размера структуры, у которой используется только несколько членов.
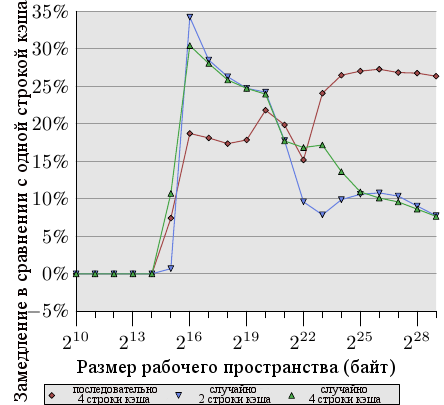
Рисунок 6.2: Распостранение на несколько строк кэша
Рисунок 6.2 показывает результаты еще одного набора тестов, использующих хорошо теперь известную программу. На этот раз складываются два значения из одного элемента списка. В одном случае оба элемента находятся в одной строке кэша, в другом случае один элемент в первой строке кэша элемента списка, а второй элемент - в последней строке кэша. График показывает замедление, которое мы имеем.
Неудивительно, что во всех случаях нет отрицательных эффектов, если рабочее пространство помещается в L1d. Когда L1d больше не хватает, приходится платить использованием двух строк кэша вместо одной. Красная линия показывает данные, когда список лежит последовательно в памяти. Мы видим две обычные ступени: около 17% ухудшения, пока достаточно кэша L2, и 27% - когда нужно использовать основную память.
В случае произвольного доступа данные выглядят немного по-другому. Ухудшение при рабочем пространстве, которое помещается в L2, находится между 25% и 35%. Потом оно уменьшается до примерно 10%. Это не из-за того, что издержки уменьшаются, наоборот, реальный доступ к памяти становится непропорционально более дорогим. Данные также показывают, что в некоторых случаях расстояние между элементами имеет значение. Кривая "случайные 4 строки кэша" показывает большие издержки, так как используются первая и четвертая строки кэша.
Легкий способ увидеть расположение структуры данных в строках кэша - это использовать программу pahole (см. [1]). Эта программа исследует структуры данных, определенные в бинарнике. Возьмем программу, содержащую такое определение:
struct foo {
int a;
long fill[7];
int b;
};
При компиляции на 64-битной машине вывод pahole содержит (кроме всего прочего) информацию, показанную на рисунке 6.3.
struct foo { int a; /* 0 4 */ /* XXX 4 bytes hole, try to pack */ long int fill[7]; /* 8 56 */ /* --- cacheline 1 boundary (64 bytes) --- */ int b; /* 64 4 */ }; /* size: 72, cachelines: 2 */ /* sum members: 64, holes: 1, sum holes: 4 */ /* padding: 4 */ /* last cacheline: 8 bytes */Рисунок 6.3: Вывод pahole Run
Этот вывод говорит о многом. Во-первых, он показывает, что структура данных использует более одной строки кэша. Программа подразумевает размер строки кэша текущего процессора, но это значение можно изменить, используя параметры командной строки. В случаях, когда размер структуры немного превосходит размер строки кэша и в памяти распределяется много объектов этого типа, особенно имеет смысл поискать пути к сжатию такой структуры. Может быть некоторые элементы могут иметь тип меньшего размера, или может быть некоторые поля в действительности являются флагами, которые могут быть реализованы, используя отдельные биты.
В случае нашего примера сжатие получить легко, оно предлагается самой программой. Вывод показывает, что есть дыра в четыре байта после первого элемента. Дыра вызвана требованиями выравнивания структуры и элемента fill. Легко видеть, что элемент b, который имеет размер четыре байта (об этом говорит 4 в конце строки), идеально подходит к этому промежутку. Результатом в этом случае является то, что промежутка больше не существует и структура данных помещается в одну строку кэша. Программа pahole может делать такую оптимизацию сама. Если использовать параметр —reorganize и добавить имя структуры в конце командной строки, выводом программы будет структура, оптимизированная по использованию строк кэша. Кроме перемещения элементов для заполнения промежутков, программа может оптимизировать битовые поля и комбинировать незначащие биты и дыры. Детали смотри в [1].
Иметь промежуток, достаточно большой для последующего элемента, - это, конечно, идеальная ситуация. Чтобы эта оптимизация была полезной, необходимо чтобы сам объект был выравнен по строке кэша. Остановимся на этом поподробнее.
Вывод pahole также позволяет легче определить, должны ли элементы быть переупорядочены так, чтобы элементы, которые вместе используются, вместе бы и хранились. Используя pahole, легко понять, какие элементы находятся в одной строке кэша и когда наоборот нужно переставить их, чтобы добиться этого. Это не автоматический процесс, но программа может сильно помочь.
- Всегда передвигать элемент структуры, который вероятнее всего будет критическим словом, в начало структуры.
- При обращении к структуре данных, когда порядок обращения не диктуется ситуацией, обращаться к элементам в том порядке, в котором они определены в структуре.
Для маленьких структур это означает, что программист должен располагать элементы в порядке, в котором они скорее всего будут использоваться. Это должно быть проделано гибко, с учетом других оптимизаций, таких как заполнение промежутков. Для более больших структур данных, эти правила должны применяться к каждому блоку размером в строку кэша.
Однако переупорядочивание элементов не стоит потраченного на него времени, если сам объект не выравнен. Выравнивание объекта определяется требованиями выравнивания типа данных. Каждый фундаментальный тип данных имеет свои требования выравнивания. Для структурных типов, наибольшие требования выравнивания из всех его элементов определяют выравнивание структуры. Это почти всегда меньше, чем размер строки кэша. Это означает, что даже если члены структуры выстроены так, чтобы попадать в одну строку кэша, сам размещенный объект может иметь выравнивание не подходящее к размеру строки кэша. Есть два пути проверить, что объект имеет выравнивание, которое использовалось при создании размещения структуры:
- объект может быть размещен в памяти с явным требованием выравнивания. При динамическом размещении вызов
mallocразместит объект с выравниванием совпадающим с выравниванием наиболее требовательного стандартного типа (обычноlong double). Однако можно использоватьposix_memalign, чтобы потребовать большего размера выравнивания.#include <stdlib.h> int posix_memalign(void **memptr, size_t align, size_t size);Эта функция сохраняет указатель на только что выделенную память в переменной
memptr. Блок памяти имеет размерsizeбайтов и выравнен по границе вalignбайтов.Для объектов, распределяемых компилятором (в
.data,.bss, и т.д., в стеке) можно использовать переменную attribute:struct strtype variable __attribute((aligned(64)));В этом случае
variableвыравнена по границе в 64 байт независимо от требования выравнивания структурыstrtype. Это работает и для глобальных, и для автоматических переменных.Однако это не работает для массивов. Только первый элемент массива будет выравнен, если размер каждого элемента массива не кратен размеру выравнивания. Это также означает, что каждая единичная переменная должна быть соответственно объявлена. Использование
posix_memalignтакже не является полностью бесплатным, так как требования выравнивания обычно ведут к фрагментации и/или более высокому потреблению памяти. - требование выравнивания типа может быть изменено, используя атрибут типа:
struct strtype { ...members... } __attribute((aligned(64)));Это заставит компилятор выделять все объекты с подходящим выравниванием, включая массивы. Однако программист должен позаботиться о запросе подходящего выравнивания для динамически размещаемых объектов. Следовательно, нужно снова использовать
posix_memalign. Удобно использовать операторalignofиз gcc и передавать значение второго параметраposix_memalign.
Ранее упомянутые в этом разделе мультимедийные расширения почти всегда требуют, чтобы доступ к памяти был выравнен. То есть, для чтения из памяти по 16 байт, адрес предполагается выравненным по 16 байт. Процессоры x86 и x86-64 имеют специальные варианты операций с памятью, которые могут осуществлять невыравненный доступ, но они медленнее. Это жесткое требование выравнивания не является новым для большинства RISC архитектур, которые требуют полного выравнивания для любого доступа к памяти. Даже если архитектура поддерживает невыравненный доступ, он иногда медленнее, чем использование соответствующего выравнивания, особенно если невыравненное чтение или запись должны использовать две строки кэша вместо одной.
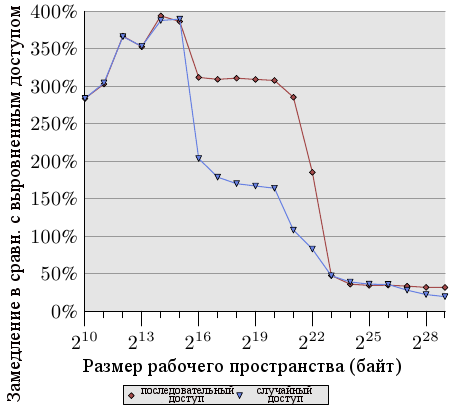
Рисунок 6.4: Отставание невыравненного доступа
Рисунок 6.4 показывает эффекты невыравненного доступа к памяти. Описанный выше тест измеряет время обращения к элементам данных (последовательным или произвольным в памяти), причем один раз список элементов выравнен в памяти, а один раз выравнивание намеренно нарушено. График показывает замедление программы, вызванное невыравненным доступом. Эффект более значительный для случая последовательного доступа по сравнению со случайным доступом потому что в последнем случае затраты на невыравненный доступ частично скрыты более высокими общими затратами на доступ к памяти. В случае последовательного доступа, для размеров рабочего пространства, умещающихся в кэш L2, замедление порядка 300%. Это может быть объяснено снижением эффективности кэша L1. Некоторые операции приращения теперь затрагивают две строки кэша, и обращение к элементу списка теперь требует чтения двух строк кэша. Соединение между L1 и L2 просто слишком перегружено.
Для очень больших размеров рабочего пространства эффект невыравненного доступа составляет от 20% до 30%, что все еще много, учитывая что выравненный доступ для таких размеров долог. Этот график должен показать, что к выравниванию нужно подходить серьезно. Даже если архитектура поддерживает невыравненный доступ, к нему не нужно относится так, как если бы он был так же хорош, как выравненный.
Однако, есть некоторые отступления от этих требований выравнивания. Если автоматическая переменная имеет требование выравнивания, то компилятор должен проследить, чтобы это происходило во всех случаях. Это нетривиальная задача, так как компилятор не имеет контроля над местами вызова и тем, как они обращаются со стеком. Эта проблема может быть решена двумя путями:
- Сгенерированный код активно выравнивает стек, вставляя промежутки при необходимости. Это требует от кода проверки на выравнивание, создания выравнивания и, позднее, отмены выравнивания.
- Требовать, чтобы все вызовы выравнивали стек.
Все обычно используемые двоичные интерфейсы приложений (ABI - application binary interface) идут вторым путем. Программы скорее всего дадут сбой, если вызов нарушает правило и вызываемое требует выравнивания. Однако поддержка выравнивания не дается бесплатно.
Размер стека функции не обязательно кратен размеру, по которому идет выравнивание. Это означает, что необходимо заполнение, если другие функции вызываются из этого стека. Другое дело, что размер стека в большинстве случаев известен компилятору и, следовательно, он знает как подстроить указатель стека, чтобы любая функция, вызываемая из стека была выравнена. На самом деле, большинство компиляторов просто округляют размер стека, чтобы сделать это.
Это простое решение невозможно, если используются массивы переменной длины или alloca. В этом случае общий размер стека известен только во время выполнения. В таком случае, возможно, понадобится активный контроль за выравниванием, что сделает сгенерированный код (немного) медленнее.
На некоторых архитектурах только мультимедийные расширения требуют выравнивания, стеки на таких архитектурах всегда минимально выравнены для обычных типов данных, обычно по 4 или 8 байт для 32- и 64-битовых архитектур соответственно. На таких системах принудительное выравнивание приносит ненужные затраты. Это означает, что в этом случае мы можем захотеть избавиться от строгих требований выравнивания, если мы знаем что от него ничего не зависит. Замыкающие функции (которые не вызывают другие функции), не исполняющие мультимедийных операций, не нуждаются в выравнивании. Также как и функции, которые вызывают только функции, не нуждающиеся в выравнивании. Если может быть идентифицирован достаточно большой набор функций, программа может захотеть ослабить требование выравнивания. Для бинарников x86 gcc имеет поддержку для ослабленных требований выравнивания стека:
-mpreferred-stack-boundary=2
Если в этой опции задано значение N, то требование выравнивания для стека будет задано как 2N байт. Так, если исползуется значение 2, то требование выравнивания для стека будет снижено со значения по умолчанию (которое равно 16 байт) до всего 4 байт. В большинстве случаев это означает, что не нужно никаких дополнительных операций выравнивания, так как обычные операции кэша push и pop и так работают по четырехбайтным границам. Эта машиннозависимая опция может помочь уменьшить размер кода и улучшить скорость выполнения. Но её невозможно применять на множестве других архитектур. Даже на x86-64 это в общем неприменимо, так как x86-64 ABI требует, чтобы параметры с плавающей точкой передавались в регистр SSE, а инструкции SSE требуют полного 16-байтного выравнивания. Тем не менее, когда эта опция применима, она может оказать заметное влияние.
Эффективное размещение элементов структуры и выравнивание - не единственные аспекты структур данных, которые влияют на эффективность кэша. Если используется массив структур, все определения структур влияют на производительность. Вспомните результаты на рисунке 3.11: в этом случае мы имели увеличивающийся размер неиспользуемых данных в элементах массива. Результатом было то, что предварительная выборка была все менее эффективной и программа, для больших объемов данных, стала менее эффективной.
Для больших размеров рабочего пространства важно использовать доступный кэш так хорошо, как это возможно. Чтобы добиться этого, возможно, будет необходимо преобразовать структуру данных. Хотя для программиста удобнее хранить все данные, которые концептуально объединены вместе, в одной структуре данных, это может оказаться не лучшим подходом с точки зрения производительности. Предположим, что у нас есть следующая структура данных:
struct order {
double price;
bool paid;
const char *buyer[5];
long buyer_id;
};
Далее, предположим, что эти записи хранятся в большом массиве и часто запускаемая процедура добавляет ожидаемые платежи по выставленные счетам. При таком сценарии, память, используемая для полей buyer и buyer_id, без необходимости загружается в кэш. Судя по данным рисунка 3.11, программа будет работать в 5 раз хуже, чем она могла бы.
Намного лучше разделить структуру данных order на две структуры, в первой используя первые два поля, остальные поля где-то еще. Это изменение определенно усложнит программу, но выигрыш в производительности может оправдать затраты.
И наконец, давайте рассмотрим еще одну оптимизацию использования кэша, которая, хотя и применима к другим кэшам, в первую очередь чувствуется при доступе к L1d. Как видно из рисунка 3.8, возрастающая ассоциативность кэша улучшает обычные операции. Чем больше кэш, тем обычно выше ассоциативность. Кэш L1d слишком велик, чтобы быть полностью ассоциативным, но не настолько велик, чтобы иметь такую же ассоциативность как L2. Это может быть проблемой, если много объектов рабочего пространства попадают в один и тот же набор кэша. Если это приводит к исключению из кэша из-за перегруженности набора, программа может испытывать задержки, даже если большая часть кэша свободна. Эти промахи кэша иногда называют конфликтные промахи. Так как адресация L1d использует виртуальные адреса, это то, над чем программист может иметь контроль. Если переменные, которые вместе используются, хранятся тоже вместе, то вероятность того, что они попадут в один набор минимальна. Рисунок 6.5 показывает как быстро проблема может появиться.

Рисунок 6.5: Эффекты ассоциативности кэша
На рисунке - знакомый теперь тест Follow с NPAD=15 {тест производился на 32-битной машине, следовательно
NPAD=15 означает одну 64-байтную строку кэша на один элемент списка.}, измеренный специальным образом. На оси X - расстояние между двумя элементами списка, измеренное пустыми элементами списка. Другими словами, расстояние в 2 означает, что адрес следующего элемента находится через 128 байт от предыдущего. Все элементы размещены в виртуальном адресном пространстве на одном расстоянии друг от друга. Ось Y показывает общую длину списка. Используется только 16 элементов, что означает, что общее рабочее пространства будет составлять от 64 до 1024 байт. Ось Z показывает среднее количество циклов, необходимое для обхода каждого элемента списка.
Результат, показанный на рисунке, не должен вызвать удивления. Если используется мало элементов, то все они помещаются в L1d и время доступа составляет только 3 цикла на элемент списка. То же верно для почти всех размещений элементов списка: виртуальное адресное пространство отлично отображается в слоты L1d, почти без конфликтов. Есть два (на этом графике) особых значения расстояния, для которых ситуация другая. Если расстояние кратно 4096 байтам (т.е. дистанции в 64 элемента) и длина списка больше, чем восемь, то среднее количество циклов для доступа к элементу списка возрастает драматически. При такой ситуации все записи находятся в одном наборе и когда длина списка больше, чем ассоциативность, записи исключаются из L1d и должны быть заново считаны из L2 при следующем обходе. Результатом является 10 циклов на элемент списка.
Из этого графика мы можем определить, что процессор использует кэш L1d размером 32Кб и ассоциативностью 8. Это означает, что тест, при необходимости, может быть использован для определения этих значений. Те же эффекты могут быть измерены для кэша L2, но там ситуация сложнее, так как L2 использует физические адреса и он намного больше.
Для программистов это означает, что ассоциативность - это то, на что стоит обращать внимание. Размещать данные на границах, являющихся степенью двойки, в реальной жизни приходится достаточно часто, а это как раз та ситуация, которая может легко привести к описанным выше эффектам и снижению производительности. Невыравненные доступы могут увеличить вероятность конфликтных промахов, так как каждый доступ может потребовать дополнительной строки кэша.

Рисунок 6.6: Адреса банков L1d у AMD
Если выполнена такая оптимизация, то возможна ещё одна похожая оптимизация. Процессоры AMD, по крайней мере, реализуют L1d как несколько индивидуальных банков. L1d может получать два слова за цикл, но только если оба слова хранятся в разных банках, или в банке с одинаковым индексом. Адрес банка закодирован в младших битах виртуального адреса, как показано на рисунке 6.6. Если переменные, которые используются вместе, сохраняются также вместе, высока вероятность того, что они в разных банках, или в одном банке с одинаковым индексом.
6.2.2 Оптимизация доступа к кэшу инструкций уровня 1
Для подготовки кода для правильного использования L1i необходимы приемы, похожие на те, что применяются при правильном использовании L1d. Проблема однако в том, что программист обычно не может прямо влиять на то, как используется L1i, если он не пишет код на ассемблере. Если используется компилятор, то программист может задать механизм использования L1i не напрямую, а руководя компилятором в составлении наилучшего устройства кода.
Код имеет то преимущество, что между переходами он линеен. В такие периоды процессор может эффективно делать предварительную загрузку памяти. Переходы нарушают эту идеальную картину из-за того что
- цель перехода может быть определена не статически;
- даже если она определена статически, загрузка памяти может занять длительное время, если эта цель
отсутствует во всех кэшах.
Эти проблемы создают задержки при выполнении кода с возможным существенным снижением производительности. Вот почему современные процессоры плотно завязаны на предсказание ветвления (BP - branch prediction). Высокоспециализированные модули BP пытаются определить цель перехода настолько задолго до самого перехода, насколько возможно, так что процессор смог бы инициировать загрузку инструкций с нового места в кэш. Они используют статические и динамические правила и все лучше и лучше распознают шаблоны при исполнении кода.
Для кэша инструкций получить данные так скоро, как это возможно, еще более важно. Как упоминалось в разделе 3.1, инструкции должны быть декодированы, прежде чем они будут исполнены и, чтобы ускорить это (важно для x86 и x86-64), инструкции кэшируются в декодированной форме, а не в форме байт/слово, читаемой из памяти.
Чтобы достичь наилучшего использования L1i, программисты должны стремиться, по крайней мере, к следующим аспектам генерации кода:
- нужно уменьшать насколько возможно размер кода. Это должно быть сбалансировано с такими оптимизациями как развертывание цикла и использование встроенных функций
- исполнение кода должно быть линейным, без пузырей. {Пузырями называются дыры в конвейере процессора, которые появляются, когда процессор ожидает ресурсы. Подробности читатель может найти в литературе по дизайну процессоров.}
- нужно выравнивать код, когда это имеет смысл.
Теперь посмотрим на некоторые методы компиляторов, способные оптимизировать программы в соответствии с этими аспектами.
У компиляторов есть опции по установке уровней оптимизации, некоторые специфические оптимизации могут быть заданы отдельно. Много оптимизаций, установленных на высоких уровнях оптимизации (-O2 и -O3 для gcc), имеют дело с оптимизацией циклов и встраиванием функций. В общем, это хорошие оптимизации. Если код, оптимизированный таким образом, отвечает за значительную часть общего времени исполнения программы, общая производительность будет улучшена. Встраивание функций, в частности, позволяет компилятору оптимизировать за раз более крупные куски кода, что, в свою очередь, приводит к генерации машинного кода, который лучше использует конвейерную архитектуру процессора. Работа над кодом и данными (через dead code elimination или value range propagation и др.) идет лучше, когда более крупные части программы могут рассматриваться как единый модуль.
Более крупный размер кода означает большую нагрузку на кэши L1i (и также L2 и более высокие уровни). Это может ухудшать производительность. Маленький код может быть быстрее. К счастью gcc имеет связанную с этим опцию оптимизации. Если используется -Os, то компилятор оптимизирует размер кода. Те оптимизации, которые могут увеличить размер кода, отключаются. Использование этой опции часто приводит к неожиданным результатам. Эта опция может дать большой выигрыш, особенно если компилятор в действительности не может извлечь выгоды из развертывания циклов и использования встроенных функций.
Использованием встроенных функций можно также управлять индивидуально. У компилятора есть ограничения и эвристика, которые управляют использованием встроенных функций. Программист может управлять этими ограничениями. Опция -finline-limit определяет, насколько велика должна быть функция, чтобы считаться слишком большой для встраивания. Если функция вызывается из нескольких мест, то встраивание её во все эти места приведет к взрывному росту размера кода. И больше того. Предположим, что функция inlcand вызывается в двух функциях f1 и f2. Функции f1 и f2 сами вызываются последовательно
Со встраиванием Без встраивания Таблица 6.3: Со встраиванием и без
Таблица 6.3 показывает как может выглядеть сгенерированный код в случаях встраивания и отсутствия встраивания в обеих функциях. Если функция inlcand встроена и в f1 и в f2, то общий размер сгенерированного кода:
размерf1+ размерf2+ 2 × размерinlcand
Без встраивания общий размер меньше на размер inlcand. Вот настолько нужно больше кэша L1i и L2, если f1 и f2 вызываются одна за другой через небольшой промежуток времени. Плюс, если inlcand не встроена, то её код может быть все ещё в L1i и её не нужно будет снова декодировать. Плюс модуль предсказания ветвлений может работать лучше при предсказании переходов, так как он уже видел этот код. Если в компиляторе значение по умолчанию для верхнего предела размера встраиваемых функций не лучшее для программы, то его необходимо понизить.
Есть случаи, однако, когда встраивание всегда имеет смысл. Если функция вызывается один только раз, то её можно встроить. Это дает возможность компилятору выполнить другие оптимизации (такие как value range propagation, которая может значительно улучшить код). Такое встраивание может быть нарушено заданными ограничениями. В gcc для таких случаев имеется опция, позволяющая определить, что функция всегда встраивается. Добавление атрибута always_inline к функции заставляет компилятор всегда её встраивать.
В том же контексте, если функция никогда не должна быть встроена, несмотря на то, что она достаточно мала, можно использовать атрибут noinline. Использование этого атрибура имеет смысл даже для маленьких функций, если они вызываются часто и из разных мест. Если можно повторно использовать содержимое L1i и общий размер кода снижен, это часто оправдывает затраты на дополнительный вызов функции. Современное предсказание ветвления работает очень хорошо. Если встраивание может привести к более агрессивным оптимизациям, то все выглядит по-другому. Это то, что нужно решать в каждом конкретном случае.
Атрибут always_inline работает хорошо, если встраиваемый код всегда используется. А что если нет? Что если встраиваемая функция используется изредка?
void fct(void) {
... code block A ...
if (condition)
inlfct()
... code block C ...
}
Код, сгенерированный для такого кода, в целом совпадет со структурой источника. Это значит, что сначала будет блок A, затем условный переход, который, если условие будет вычислено как ложь, приведет к скачку вперед. Затем идет код, сгенерированный для встроенной функции inlfct и, в конце, блок кода C. Это все выглядит разумно, но есть проблема.
Если condition часто принимает значение ложь, то выполнение не будет линейным. Будет большой кусок неиспользуемого кода в центре, который не только загрязняет L1i из-за предварительной выборки, но и может вызвать проблемы с предсказанием ветвлений. Если предсказание ветвления неверно, то условный переход может быть очень неэффективным.
Это общая проблема, не специфическая только для встраиваемых функций. Всегда, когда есть однобокое условное выполнение (то есть когда выражение в условном переходе намного чаще выдает один результат, чем другой), есть потенциальная опасность неверного статического предсказания ветвления и, следовательно пузырей в конвейере. Это может быть предотвращено указанием компилятору передвинуть реже используемый код подальше от основного пути кода. В этом случае условная ветвь, сгенерированная для конструкции if, перескочит в другое место, так как показано на картинке.
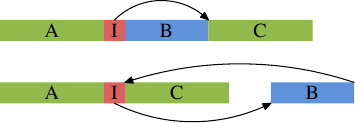
Верхняя часть представляет собой простой план кода. Если часть B, то есть часть, сгенерированная для встраиваемой функции inlfct, часто пропускается при выполнении потому, что условие I перепрыгивает через него, то предварительная выборка процессором будет помещать в кэш строки, содержащие блок B, который редко используется. Используя перестановку блоков, можно изменить это и получить результат из нижней части картинки. Часто исполняемый код линеен в памяти, а редко исполняемый передвинут туда, где он не помешает предварительной выборке и эффективности L1i.
GCC предоставляет два метода, чтобы добиться этого. Во-первых, компилятор может учесть выводы программы сбора информации о выполнении при перекомпиляции кода и переставить блоки кода с учетом этого. Мы увидим как это работает в разделе 7. Второй метод использует явное предсказание ветвей. Gcc использует __builtin_expect:
long __builtin_expect(long EXP, long C);
Эта конструкция говорит компилятору о том, что выражение EXP скорее всего примет значение C. Возвращаемым значением будет EXP. Предполагается, что __builtin_expect будет использоваться с условным выражением. Почти всегда это будет выражение с булевым значением, поэтому удобно определить два вспомогательных макроса:
#define unlikely(expr) __builtin_expect(!!(expr), 0) #define likely(expr) __builtin_expect(!!(expr), 1)
Эти макросы можно использовать так:
if (likely(a > 1))
Если программист использует эти макросы и потом использует опцию оптимизации -freorder-blocks, gcc переупорядочит блоки как на картинке выше. Эта опция включена для -O2, но выключена для -Os. Есть еще одна опция для перестановки блоков (-freorder-blocks-and-partition), но она имеет ограниченное применение, так как не работает с обработкой исключений.
Есть еще одно большое преимущество маленьких циклов, по крайней мере на некоторых процессорах. Интерфейс Intel Core 2 имеет специальное свойство, называемое Детектор Потока Цикла (Loop Stream Detector - LSD). Если цикл состоит не более чем из 18 инструкций (ни одна из которых не является вызовом подпрограммы), требует не более 4 вызовов декодера по 16 байт, имеет не более 4 инструкций ветвления и выполняется более 64 раз, то такой цикл иногда закрепляется в очереди инструкций и, следовательно, быстрее доступен при следующем использовании. Это применимо, например, к маленьким внутренним циклам, которые запускаются много раз через внешний цикл. И даже без такого специального железа компактные циклы имеют преимущества.
Встраивание - не единственный аспект оптимизации по отношению к L1i. Другой аспект - это выравнивание, так же как и для данных. Есть очевидные отличия: код является по большей части линейным двоичным объектом, который нельзя произвольным образом разместить в памяти и на который программист не влияет непосредственно, из-за того, что он генерируется компилятором. Есть, однако, некоторые аспекты, на которые программист может влиять.
Не имеет никакого смысла выравнивать каждую отдельную инструкцию. Цель состоит в том, чтобы поток инструкций был последовательным. Поэтому выравнивание имеет смысл только в стратегических местах. Чтобы решить, куда добавлять выравнивания, нужно понимать в чем могут состоять преимущества. Нахождение инструкции в начале строки кэша {Для некоторых процессоров строка кэша не совпадает с атомарными блоками инструкций. Интерфейс Intel Core 2 передает декодеру 16-байтные блоки. Они выравнены и поэтому не могут выйти за границы строк кэша. Выравнивание по началу строки кэша имеет однако преимущества, так как оптимизирует позитивный эффект предварительной выборки.} означает, что предварительная выборка строки кэша максимизирована. Для инструкций это также означает, что декодер более эффективен. Легко видеть, что если инструкция выполняется в конце строки кэша, то процессор должен подготовиться прочесть следующую строку кэша и декодировать инструкции. Но есть вещи, которые могут пойти неправильно (такие как промахи кэша), что означает, что в среднем инструкции в конце строки кэша выполняются не так эффективно, как в начале.
Соедините это с тем, что проблема может быть еще серьезнее, если управление только что было перенесено к рассматриваемой инструкции (и, следовательно, предварительная выборка неэффективна) и мы придем к окончательному заключению о том, где выравнивание наиболее полезно:
- в начале функций;
- в начале блоков, которые могут быть достигнуты только перескакиванием через предыдущий код;
- до некоторой степени в начале циклов.
В первых двух случаях выравнивание происходит с небольшими затратами. Выполнение кода продолжается с нового места, и если мы разместим его в начале строки кэша, то мы оптимизируем предварительную выборку и декодирование. {Для декодирования инструкций процессоры часто используют меньший чем размер строки кэша блок, 16-байтный в случае x86 и x86-64.} Компилятор выполняет выравнивание, вставляя где нужно инструкции no-op, чтобы заполнить пустые места, созданные выравниванием. Этот ⌠мертвый код■ занимает немного места и обычно не влияет на производительность.
Третий случай немного отличается: выравнивание начала каждого прохода цикла может создать проблемы для производительности. Проблема в том, что к началу цикла программа часто подходит последовательно. При неудачных обстоятельствах выравнивание начала цикла приведет к появлению пустоты между началом цикла и предыдущей инструкцией. В отличие от первых двух случаев, эта пустота не может быть мертвым кодом. После предыдущей инструкции должна исполняться первая инструкция цикла. Это означает, что после предыдущей инструкции нужно вставить или несколько инструкций no-op, или бузусловный переход к первой инструкции цикла. Ни то, ни другое не бесплатно. Если цикл выполняется немного раз, то эти инструкции no-op или безусловный переход могут стоить больше, чем выигрыш от выравнивания цикла.
Есть три способа, с помощью которых программист может влиять на выравнивание кода. Очевидно, что если код написан на ассемблере, то функция и все инструкции могут быть явным образом выравнены. Для этого ассемблер предоставляет для всех архитектур директиву .align. Для языков высокого уровня нужно сообщать компилятору о требованиях выравнивания. В отличие от типов данных и переменных, это невозможно сделать в исходном коде. Вместо этого используется опция компиляции:
-falign-functions=N
Эта опция заставляет компилятор выравнивать все функции по ближайшей большей N степени двойки. Это означает, что появляется дыра размером до N байт. Для маленьких функций использование большого значения N будет расточительством. Равно как и для кода, который выполняется редко. Последнее может часто происходить в библиотеках, которые могут содержать как популярные, так и не очень популярные интерфейсы. Мудрый выбор этой опции может ускорить выполнение или сохранить память избегая выравнивания. Все выравнивание может быть отключено используя единицу в качестве значения N или используя опцию -fno-align-functions.
Выравнивание для второго случая, упомянутого выше — в начале блоков, которые могут быть достигнуты только перескакиванием через предыдущий код — может контролироваться другой опцией
-falign-jumps=N
Все остальные детали эквивалентны, применимо то же предупреждение о ненужном расходе памяти.
Третий случай также имеет свою опцию:
-falign-loops=N
И снова применимы те же детали и предупреждения. Исключая то, что, как объяснялось выше, выравнивание отрицательно влияет на выполнение, так как либо инструкции no-op, либо бузусловный переход должны быть выполнены, если выравниваемый адрес достигается последовательно.
У gcc есть ещё одна опция для контроля над выравниванием, которую упомянем только для полноты. Опция -falign-labels выравнивает каждый ярлык в коде (в основном начало каждого блока). Это всегда, кроме редких исключений, замедляет код и, следовательно, не должно использоваться.
6.2.3 Оптимизация доступа к кэшу уровня 2 и выше
Все, что было сказано об оптимизации кэша уровня 1 также применимо и к уровню 2 и выше. Есть два дополнительных аспекта для кэша последнего уровня:
- промахи кэша всегда очень дороги. В то время как промахи L1 (вероятно) часто будут найдены в L2 или более высоких уровнях кэша, ограничивая, следовательно, ущерб, у кэша последнего уровня такого резерва, очевидно, нет.
- кэш уровня L2 и выше часто является общим для нескольких ядер и/или гиперпотоков. Следовательно эффективный размер кэша, доступный для каждого модуля исполнения, обычно меньше, чем общий размер кэша.
Чтобы избежать высоких затрат при промахах кэша, размер рабочего пространства должен соответствовать размеру кэша. Если данные используются только один раз, то и это необязательно, так как кэш все равно будет неэффективным. Мы говорим о такой работе, при которой набор данных используется больше, чем один раз. В этом случае использование рабочего пространства слишком большого, чтобы поместиться в кэш, приведет к большому количеству промахов кэша, которые, даже если предварительная выборка будет успешно работать, замедлят программу.
Программа должна делать свою работу, даже если набор данных очень велик. Это задача программиста - организовать работу так, чтобы минимизировать промахи кэша. Для кэшей последного уровня, так же как и для L1, это возможно, если разбивать задачу на маленькие кусочки. Это очень похоже на оптимизацию умножения матриц в таблице 6.2. Одно различие состоит в том, что блоки данных, над которыми нужно работать, могут быть больше. Код становится ещё сложнее, если оптимизация работы с L1 также нужна. Вообразите умножение матриц, при котором наборы данных (две исходные матрицы и матрица результата) не помещаются вместе в кэш последнего уровня. В этом случае возможно придется оптимизировать доступ к L1 и кэшу последнего уровня одновременно.
Размер строки кэша L1 обычно постоянен для многих поколений процессоров, и даже если это не так, то разница будет невелика. Не представляет большой проблемы предполагать больший размер. На процессорах с меньшим размером будет использоваться две или более строк кэша вместо одной. В любом случае будет разумным оптимизитовать код под размер строки кэша.
Для кэшей высокого уровня это не так, если предполагается, что программа будет универсальной. Размеры этих кэшей могут варьироваться в широких пределах. Различие в 8 раз не является чем-то необычным. Невозможно предположить большой размер кэша как значение по умолчанию, так как это будет означать, что код будет выполняться плохо на всех машинах, кроме тех, у которых действительно такой большой кэш. Противоположный выбор также плох - предполагая самый маленький кэш, мы отбросим 87% кэша или больше. Это плохо, как мы можем увидеть из рисунка 3.14, использование большого кэша может иметь огромный эффект на скорость программы.
Все это означает, что код должен динамически подстраиваться под размер строки кэша. Эта оптимизация индивидуальна для программы. Все что мы можем сказать здесь - это то, что программист должен корректно вычислить требования программы. Нужны не только сами наборы данных, кэши высшего уровня также используются для других целей, например все выполняемые инструкции загружаются из кэша. Если используются библиотечные функции, то использование кэша может подскочить до значительных размеров. Этим библиотечным функциям могут понадобиться собственные данные, что ещё более уменьшит доступную память.
Как только у нас есть формула требований памяти, мы можем сравнить её с размером кэша. Как упоминалось ранее, кэш может быть общим для нескольких ядер. В настоящее время {Определенно когда-нибудь будет лучшее решение!} единственный путь получить корректную информацию без знания тонкостей устройства аппаратуры - это через файловую систему /sys. В таблице 5.2 мы видим, что ядро сообщает об аппаратном обеспечении. Программа должна найти директорию:
/sys/devices/system/cpu/cpu*/cache
для кэша последнего уровня. Её можно узнать по наивысшему числовому значению в файле level этой директории. Когда директория идентифицирована, программа должна прочитать содержимое файла size в этой директории и разделить числовое значение на число бит, заданное в маске в файле shared_cpu_map.
Значение, подсчитанное таким образом - это безопасный нижний предел. Иногда программа знает немного больше о поведении остальных потоков и процессов. Если эти потоки запланированы при разделении кэша ядрами или гиперпотоками, и использование кэша при этом не полностью задействует свою долю общего размера кэша, тогда вычисленный предел может быть меньше оптимального. Нужно ли увеличивать эту долю, зависит от ситуации. Программист должен сделать выбор или позволить сделать выбор пользователю.
6.2.4 Оптимизация использования TLB
Есть два вида оптимизации использования TLB. Первый вид оптимизации - это снизить количество страниц, которые использует программа. Это автоматически приводит к снижению количества промахов TLB. Второй вид оптимизации - это сделать поиск TLB дешевле снижением количества страниц каталога высокого уровня, которые должны быть размещены в памяти. Меньшее количество страниц означает меньшее использование памяти, что может привести к более высокому проценту попаданий кэша при поиске в каталоге.
Первая оптимизация тесно связана с минимизацией ошибок страниц. Мы подробнее обсудим эту тему в разделе 7.5. В то время как ошибки страниц - это обычно одноразовые потери, промахи TLB - это потери постоянные, учитывая то, что кэш TLB обычно маленький и часто очищается. Ошибки страниц обходятся дороже на порядки, чем промахи TLB, но если программа выполняется достаточно долго и определенные части программы выполняются достаточно часто, то промахи TLB могут даже перевесить ошибки страниц. Следовательно, важно рассматривать оптимизацию страниц не только как связанную с ошибками страниц, но и с промахами TLB тоже. Разница здесь в том, что в то время как оптимизация ошибок страниц требует только группировки кода и данных по ширине страницы, оптимизация TLB требует, чтобы в каждый момент времени использовалось как можно меньше записей TLB.
Вторую оптимизацию TLB ещё тяжелее контролировать. Количество используемых каталогов страниц зависит от распределения диапазонов адресов, используемых в виртуальном адресном пространстве процесса. Широко варьирующиеся местоположения в адресном пространстве означают большее количество каталогов. Сложность состоит в том, что рандомизация местоположения адресов (ASLR - Address Space Layout Randomization) как раз и приводит к такой ситуации. Загрузка адресов стека, DSO, кучи и, возможно, исполняемого файла рандомизируется во время выполнения, для того чтобы предотвратить атаки на машину с помощью подбора адресов функций или переменных.
Для максимальной производительности ASLR определенно должна быть отключена. Однако стоимость дополнительных каталогов довольно низкая, чтобы сделать этот шаг ненужным всегда, кроме нескольких экстремальных случаев. Одна возможная оптимизация, которую ядро может выполнить в любое время, - это убедится, что каждое отображение не нарушает границы адресного пространства между двумя каталогами. Это немного ограничит ASLR, но не настолько, чтобы существенно ослабить её.
Единственный случай, когда программист непосредственно сталкивается с этим, - это когда регион адресного пространства запрашивается явным образом. Это получается при использовании mmap с MAP_FIXED. Распределять новый регион адресного пространства таким образом очень опасно и это редко используется. Это однако возможно и, если это используется, то программист должен знать о границах каталогов страниц последнего уровня и выбирать запрашиваемый адрес подходящим образом.
6.3 Предварительная загрузка
Цель предварительной загрузки состоит в том, чтобы спрятать задержку доступа к памяти. Конвейер команд и способность современных процессоров выполнять их не по порядку (OOO - out-of-order), позволяет прятать часть задержки, но, в лучшем случае, для тех доступов к памяти, которые находятся в кэше. Чтобы покрыть задержку доступа к основной памяти, очередь команд должна быть невероятно большой. Некоторые процессоры без OOO пытаются компенсировать это увеличением числа ядер, но это не равноценный обмен, если только весь используемый код не распараллелен.
Предварительная загрузка может помочь ещё больше скрыть задержку. Процессор выполняет предварительную загрузку сам, вследствие наступления определенных событий (аппаратная предварительная загрузка) или по запросу от программы (программная предварительная загрузка).
6.3.1 Аппаратная предварительная загрузка
Триггером аппаратной предварительной загрузки обычно являются два или более промаха кэша, соответствующие определенному образцу. Эти промахи кэша могут быть в последующей или предыдущей строке кэша. В старых реализациях распознавались только промахи кэша в смежных строках. В современной аппаратуре распознаются и более дальние промахи, то есть промах через фиксированное количество строк кэша тоже подходит под образец и обрабатывается соответственно.
Для производительности было бы плохо, если бы каждый промах кэша вызывал аппаратную предварительную загрузку. Случайный доступ к памяти, например к глобальным переменным, - дело обычное и предварительная загрузка привела бы только к ненужным тратам пропускной способности FSB. Вот почему для того, чтобы начать предварительную загрузку, требуется по крайней мере два промаха кэша. Современные процессоры всегда предполагают, что есть больше чем один поток доступов к памяти. Процессор пытается автоматически присвоить промах кэша такому потоку, и если достигнуто предельное значение, начинает аппаратную предварительную загрузку. Современные процессоры могут отслеживать от восьми до шестнадцати различных потоков для высших уровней кэша.
Модули, отвечающие за распознавание образцов, закреплены за соответствующими кэшами. Могут иметься модули предварительной загрузки для кэшей L1d и L1i. Очень большая вероятность того, что имеется модуль для кэшей L2 и выше. Этот модуль для L2 и выше разделяется между всеми ядрами и гиперпотоками, использующими общий кэш. Следовательно количество от восьми до шестнадцати отдельных потоков быстро уменьшается.
Предварительная загрузка имеет одну большую слабость - она ме может пересекать границы страницы. Причина должна быть очевидной, если вспомнить, что ЦПУ поддерживают выделение страниц по запросу. Если модуль предварительной загрузки сможет пересекать границы страницы, то такой доступ пожет породить событие операционной системы, делающее эту страницу доступной. Это само по себе плохо, особенно для производительности. Что еще хуже, это то, что модуль предварительной загрузки ничего не знает о семантике программы и самой операционной системы. Это может, следовательно, привести к предварительной загрузке страниц, которые в реальной жизни никогда бы не потребовались. Это означает, что модуль предварительной загрузки вышел бы край региона памяти, к которому процессор до этого имел доступ по узнаваемому образцу. Это не только возможно, так скорее всего и будет. Если процессор вызовет, как побочный эффект предварительной загрузки, запрос такой страницы, операционная система может быть совсем сбита с толку, если такой запрос в противном случая никогда бы не состоялся.
Следовательно важно понимать, что независимо от того, насколько хорош модуль предварительной загрузки в предсказании по образцу, программа будет получать промахи кэша на границе страницы, если она явно не делает предварительную загрузку или не читает из новой страницы. Это ещё одна причина оптимизировать размещение данных, как описано в разделе 6.2, чтобы минимизировать загрязнение кэша, не помещая туда несвязанные данные.
Из-за этого ограничения со страницами процессоры не имеют очень уж сложной логики распознавания образцов для предварительной загрузки. С все еще доминирующим размером страниц в 4Кб не имеет смысла делать логику сложнее. Диапазон адресов, в которых распознаются образцы, увеличивался с годами, но, возможно, не имеет смысла делать его больше чем 512 байт, как сегодня часто делают. В настоящее время модули предварительной загрузки не распознают нелинейные образцы доступа. Больше вероятность того, что такие образцы действительно случайного характера, или, по крайней мере повторяются достаточно редко, чтобы имело смысл пытаться распознать их.
Если аппаратная предварительная загрузка запускается не в нужный момент, то можно сделать немного. Одна возможность - это попытаться выявить эту проблему и немного изменить расположение данных и/или кода. С этим придется, наверное, повозиться. Могут быть специалные локализованные решения, как например использование инструкции ud2 {или не-инструкции. Это рекомендованный неопределенный машинный код.} на процессорах x86 и x86-64. Эта инструкция, которая сама по себе не выполняется, используется после неявной инструкции перехода. Она используется как сигнал загрузчику инструкций, что процессор не должен тратить усилия на декодирование последующей памяти, так как выполнение продолжится с другого места. Однако это очень особая ситуация. В большинстве случаев приходится жить с этой проблемой.
Возможно полное или частичное отключение аппаратной предварительной загрузки для всего процессора. На процессорах Intel для этого используется регистр MSR - Model Specific Register (IA32_MISC_ENABLE, бит 9 на многих процессорах; бит 19 отключает только предварительную загрузку смежных строк кэша). Это, в большинстве случаев, должно происходить в ядре, так как это привилегированная операция. Если профилирование показывает, что важное приложение, работающее в системе, страдает от нехватки полосы пропускания и преждевременного исключения из кэша, возникающего из-за аппаратной предварительной загрузки, то использование MSR возможно.
6.3.2 Программная предварительная загрузка
Преимущество аппаратной загрузки в том, что программу не нужно подстраивать. Недостатки, как только что было описано, в том, что образцы доступа должны быть тривиальными и предварительная загрузка не может пересекать границы страниц. По этим причинам у нас есть больше возможностей, программная предварительная загрузка - самая важная из них. Программная предварительная загрузка требует модификации исходного кода встраиванием специальных инструкций. Некоторые компиляторы поддерживают псевдокомментарии, для того чтобы более или менее автоматически вставлять инструкции предварительной загрузки. На x86 и x86-64 для того, чтобы вставлять эти специальные инструкции, используется соглашение Intel по встроенным функциям компилятора:
#include <xmmintrin.h>
enum _mm_hint
{
_MM_HINT_T0 = 3,
_MM_HINT_T1 = 2,
_MM_HINT_T2 = 1,
_MM_HINT_NTA = 0
};
void _mm_prefetch(void *p,
enum _mm_hint h);
Программы могут применять эту функцию _mm_prefetch к любому указателю программы. Большинство процессоров (определенно все процессоры x86 и x86-64) игнорируют ошибки, возникающие из-за недействительных указателей, что делает жизнь программиста существенно проще. Однако, если переданный указатель ссылается на действительную память, то модуль предварительной загрузки будет проинструктирован загрузить эти данные в кэш и, если нужно, вытеснить другие данные. Нужно избегать необязательных предварительных загрузок, так как они могут снизить эффективность кэша и потребляют пропускную способность памяти (возможно даже на величину двух строк кэша, если вытесняемая строка грязная).
То, какие следует использовать значения параметров функции _mm_prefetch, определяется её реализацией. Это означает, что каждая версия процессора реализует её (немного) по-разному. В общем можно сказать, что _MM_HINT_T0 загружает данные на все уровни инклюзивного кэша и на нижние уровни эксклюзивного кэша. Если элемент данных находится в высших уровнях кэша, то он загружантся в L1d. Индикатор _MM_HINT_T1 помещает данные в L2, но не в L1d. Если есть L3, то _MM_HINT_T2 делает нечто подобное. Есть однако детали, которые слабо документированы и нуждаются в проверке для каждого используемого процессора. В общем, если данные должны использоваться немедленно, то использование _MM_HINT_T0 будет правильным выбором. Конечно, это требует того, чтобы размер кэша L1d был достаточно велик, чтобы содержать все предварительно загруженные данные. Если размер немедленно используемого рабочего пространства слишком велик, то предварительная загрузка всего его в L1d будет прохой идеей и нужно использовать другие два индикатора.
Четвертый индикатор, _MM_HINT_NTA, особый, в том смысле, что он говорит процессору о том, чтобы обращаться с предварительно выбранной строкой кэша по-особому. Мы уже объясняли в разделе 6.1 что такое NTA (non-temporal aligned). Программа говорит процессору о том, что не нужно загрязнять кэш этими данными, так как они используются только короткое время. Процессор может, следовательно, во время загрузки, отказаться от чтения данных в кэш нижнего уровня для инклюзивных реализаций кэша. Когда данные выталкиваются из L1d, их не нужно помещать в L2 или выше, но можно наоборот записать прямо в память. Могут быть и другие трюки, внедренные дизайнерами процессоров, если задан этот индикатор. Программист должен быть осторожен при использовании этого индикатора: если размер немедленно испльзуемого рабочего пространства слишком велик и приводит к исключению из кэша строки, загруженной с индикатором NTA, произойдет перезагрузка из памяти.

Рисунок 6.7: Среднее с предварительной загрузкой, NPAD=31
Рисунок 6.7 показывает результаты теста, использующего знакомый теперь алгоритм погони за указателями. Список рандомизирован. Отличие от предыдущего теста в том, что программа теперь тратит некоторое время на каждый узел списка (около 160 циклов). Как мы знаем из данных рисунка 3.15, производительность программы сильно падает, когда размер рабочего пространства начинает превышать размер кэша последнего уровня.
Теперь мы можем попытаться улучшить ситуацию выпуская запросы на предварительную загрузку перед вычислением. То есть при каждом обходе цикла мы предварительно загружаем новый элемент. Расстояние между предварительно загружаемым узлом в списке и узлом, над которым идет работа, должно быть тщательно выбрано. Имея в виду, что каждый узел обрабатывается за 160 циклов и что мы должны предварительно загрузить две строки кэша (NPAD=31), расстояние в пять элементов списка будет достаточным.
Результаты на рисунке 6.7 показывают, что предварительная загрузка действительно помогает. Пока размер рабочего пространства не превышает размера кэша последнего уровня (машина имеет 512Кб = 219Б L2), числа совпадают. Инструкции предварительной загрузки не накладывают заметной дополнительной нагрузки. Как только размер L2 превышен, предварительная загрузка экономит от 50 до 60 циклов, или до 8%. Использование предварительной загрузки не прячет весь ущерб, но немного помогает.
AMD внедряет в 10 модели семейства Opteron другую инструкцию: prefetchw. Эта инструкция пока не имеет эквивалента у Intel и не доступна через встроенные функции компилятора. Инструкция prefetchw предварительно загружает строку кэша в L1 так же как и другие инструкции предварительной загрузки. Разница в том, что строка кэша немедленно переходит в состояние 'M'. Это будет недостатком, если потом не последует никакой записи в строку кэша. Если есть одна или более запись, то они будут ускорены, так как им не нужно будет изменять состояние кэша - оно уже было изменено, когда строка кэша была предварительно загружена.
Предварительная загрузка может дать гораздо больше, чем скромные 8%, которые мы получили. Но это очень трудно сделать правильно, особенно если один и тот же бинарник предполагается использовать на большом разнообразии машин. Счетчики производительности, предоставляемые ЦПУ, могут помочь программисту анализировать предварительные загрузки. События, которые могут быть подсчитаны и сравнены, включают аппаратные предварительные загрузки, программные предварительные загрузки, полезные программные предварительные загрузки, промахи кэша на разных уровнях и т.д. В разделе 7.1 мы опишем многие такие события. Все эти счетчики специфичны для каждой машины.
При анализе программ, в первую очередь нужно смотреть на промахи кэша. Когда найден большой источник промахов кэша, нужно попытаться добавить инструкции предварительной загрузки для проблематичных доступов к памяти. Добавлять эти инструкции нужно по одной за раз. Результат каждой модификации нужно проверять с помощью счетчиков, измеряющих полезные программные предварительные загрузки. Если результаты этих счетчиков не повышаются, то предварительная загрузка может быть неверна, у неё может быть слишком мало времени для загрузки из памяти, или она выталкивает из кэша память, которая все еще нужна.
Сегодня gcc может выпускать инструкции предварительной загрузки автоматически в одной ситуации. Если цикл проходит по массиву, то можно использовать следующую опцию:
-fprefetch-loop-arrays
Компилятор посчитает, имеет ли предварительная загрузка смысл, и если да, то насколько далеко вперед она должна смотреть. Для небольших массивов это может не быть полезным, если величина массива неизвестна, то результаты могут ухудшиться. Руководство по gcc предупреждает, что польза этого действия зависит от формы кода и в некоторых ситуациях код может выполняться медленнее. Программисты должны использовать эту опцию осторожно.
6.3.3 Специальный вид предварительной загрузки: условная загрузка
Способность процессора выполнять инструкции не по порядку позволяет передвигать инструкции, если они не конфликтуют друг с другом. Например (в этом примере используется IA-64):
st8 [r4] = 12 add r5 = r6, r7;; st8 [r18] = r5
Этот код сохраняет 12 в адресе, заданном регистром r4, суммирует содержимое регистров r6 и r7 и сохраняет сумму в регистре r5. И в конце сумма сохраняется в адресе, заданном регистром r18. Смысл здесь в том, что инструкция суммирования может быть выполнена до, или одновременно, первой инструкции st8, так как нет зависимости данных. Но что произойдет, если одно из слагаемых нужно загрузить?
st8 [r4] = 12 ld8 r6 = [r8];; add r5 = r6, r7;; st8 [r18] = r5
Дополнительная инструкция ld8 загружает значение из адреса, заданного в регистре r8. Есть очевидная зависимость данных между инструкцией загрузки и последующей инструкцией add (вот почему после инструкции стоит ;;, спасибо за вопрос). Критично здесь то, что новая инструкция ld8, в отличие от инструкции add, не может быть помещена перед первой st8. Процессор не может достаточно быстро определить при декодировании инструкций, конфликтуют ли сохранение и загрузка, то есть имеют ли r4 и r8 одинаковое значение. Если они действительно имеют одинаковое значение, то инструкция st8 определяет значение, загружаемое в r6. Что ещё хуже, ld8 может сделать это с большой задержкой, если произойдет промах кэша. Для этого случая архитектура IA-64 поддерживает условную загрузку:
ld8.a r6 = [r8];; [... other instructions ...] st8 [r4] = 12 ld8.c.clr r6 = [r8];; add r5 = r6, r7;; st8 [r18] = r5
Новые инструкции ld8.a и ld8.c.clr связаны друг с другом и заменяют инструкцию ld8 из предыдущего примера кода. Инструкция ld8.a - это условная загрузка. Значение не может быть использовано сразу, но процессор может начать работу. К тому моменту, когда будет достигнута инструкция ld8.c.clr, содержимое уже наверное будет загружено (если в промежутке будет достаточное количество инструкций). Аргументы этой инструкции должны совпадать с аргументами инструкции ld8.a. Если предшествующая инструкция st8 не перезаписала значение (то есть r4 и r8 одинаковые), то ничего не нужно делать. Условная загрузка делает свое дело и задержка загрузки спрятана. Если загрузка и сохранение конфликтуют, то ld8.c.clr снова делает загрузку из памяти и мы имеем семантику обычной инструкции ld8.
Условная загрузка (пока?) не является распостраненной. Но, как показывает пример, - это простой и очень эффективный способ скрыть задержки. Предварительная загрузка в основном делает то же самое, поэтому для процессоров с небольшим количеством регистров условная загрузка вероятно не имеет большого смысла. Условная загрузка имеет (иногда большое) преимущество в том, что значение загружается непосредственно в регистр, а не в строку кэша, откуда оно может быть снова исключено (например когда процессор временно переключается на работу с другим потоком). Если условная загрузка доступна, её следует использовать.
6.3.4 Вспомогательные потоки
Если кто-то пытается использовать программную предварительную загрузку, он часто сталкивается со сложностью кода. Если код проводит итерацию по некоторой структуре данных (по списку в нашем случае), то придется строить две независимые итерации в том же цикле: обычная итерация проделывает работу, а вторая итерация смотрит вперед, обеспечивая предварительную загрузку. Это может усложнить код и привести к ошибкам.
Далее, нужно определить, насколько далеко вторая итерация должна смотреть вперед. Если ненамного, то память не будет загружена вовремя. Если слишком намного, то только что загруженные данные могут быть снова исключены из кэша. Ещё одна проблема состоит в том, что инструкции предварительной загрузки, хотя они и не блокируют и не ждут пока память загрузится, отнимают время. Инструкции нужно декодировать, что может стать заметным, если декодер очень занят, например из-за хорошо написанного/сгенерированного кода. И наконец, размер кода цикла увеличивается. Это снижает эффективность L1i. Если пытаться избежать части этих затрат, выпуская несколько запросов на предварительную выборку зараз (в случае если вторая загрузка не зависит от результата первой), то можно столкнуться с проблемой появления невыполненных запросов на предварительную выборку.
Альтернативный подход состоит в том, чтобы выполнять обычные операции и предварительную загрузку совершенно независимо. Этого можно добиться используя два стандартных потока. Потоки, очевидно, должны быть запланированы так, чтобы поток предварительной загрузки заполнял кэш, используемый обоими потоками. Есть два специальных решения, достойных упоминания:
- Использовать гиперпотоки (см. рисунок 3.22) на одном ядре. В этом случае предварительная загрузка пойдет в L2 (или даже L1d).
- Использовать ⌠глупые■ потоки, которые в отличие от потоков SMT могут делать только предварительную загрузку и другие простые операции. Это опция, которую производители процессоров должны исследовать.
Использование гиперпотоков особенно интересно. Как мы видели на рисунке 3.22, разделение кэша является проблемой, когда гиперпотоки выполняют независимый код. Если наоборот, один поток используется как вспомогательный для предварительной загрузки, то проблемы нет. Напротив, это желаемый эффект, так как предварительная загрузка идет в кэш низшего уровня. Кроме того, так как поток предварительной загрузки по большей части бездействует или ждет память, обычные операции другого вспомогательного потока не сильно страдают, если он не должен сам обращаться к основной памяти. Последнее - это в точности то, что вспомогательный поток предварительной загрузки предотвращает.
Единственная хитрость здесь в том, чтобы сделать так, что вспомогательный поток не будет убегать слишком далеко вперед. Он на должен полностью заполнить кэш, так что самые старые предварительно загруженные данные были бы снова исключены. На Linux синхронизация легко может быть сделана при помощи системного вызова futex (см. [2]) или, с немного большими затратами, используя примитивы синхронизации потоков POSIX.
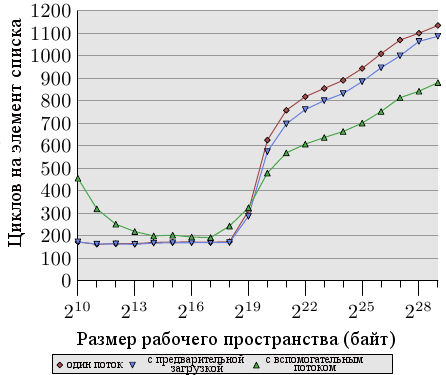
Рисунок 6.8: Среднее с вспомогательными потоками, NPAD=31
Преимущества такого подхода можно видеть на рисунке 6.8. Это тот же тест, что и на рисунке 6.7, только добавлен ещё один результат. Новый тест создает вспомогательный поток, который идет примерно на 100 записей впереди и читает (а не только делает предварительную загрузку) все строки кэша каждого элемента списка. Для этого случая мы имеем по две строки кэша на каждый элемент списка (NPAD=31 на 32-битной машине с 64-байтной строкой кэша).
Два потока запланированы на гиперпотоках на одном ядре. Тестовая машина имела только одно ядро, но результаты будут примерно те же, если ядер будет больше. Функции родства, которые мы введем в разделе 6.4.3, будут использоваться для связывания потока с соответствующим гиперпотоком.
Чтобы определить какие два (или более) процессора, которые видит операционная система, на самом деле являются гиперпотоками, можно использовать интерфейс NUMA_cpu_level_mask из libNUMA (см раздел 12).
#include <libNUMA.h>
ssize_t NUMA_cpu_level_mask(size_t destsize,
cpu_set_t *dest,
size_t srcsize,
const cpu_set_t*src,
unsigned int level);
Этот интерфейс можно использовать для того, чтобы определить иерархию процессоров и то, как они соединены через кэш и память. Нам здесь интересен уровень 1, который соответствует гиперпотокам. Чтобы запланировать два потока на двух гиперпотоках можно использовать функции libNUMA (обработка ошибок для краткости опущена):
cpu_set_t self;
NUMA_cpu_self_current_mask(sizeof(self),
&self);
cpu_set_t hts;
NUMA_cpu_level_mask(sizeof(hts), &hts,
sizeof(self), &self, 1);
CPU_XOR(&hts, &hts, &self);
После того, как этот код выполнен, мы имеем два набора битов ЦПУ. Можно использовать self, чтобы задать родство текущего потока и маска hts может быть использована, чтобы задать родство вспомогательного потока. В идеале, это должно случиться перед тем, как поток создан. В разделе 6.4.3 мы опишем интерфейс для задания родства. Если в наличии нет гиперпотоков, то NUMA_cpu_level_mask вернет 1. Это можно использовать как сигнал о том, что данной оптимизации делать не нужно.
Результат этого теста может показаться удивительным (а может и нет). Если рабочее пространство помещается в L2, то накладные расходы на вспомогательный процесс снижают производительность от 10% до 60% (мы снова игнорируем самые маленькие размеры рабочего пространства, так как в этом случае результаты неразличмы на уровне шума). Этого можно было ожидать, так как если данные уже в кэше L2, то вспомогательный процесс предварительной загрузки не помогает выполнению, а только зря расходует системные ресурсы.
Однако когда L2 исчерпан, картина меняется. Вспомогательный поток предварительной загрузки помогает сократить время выполнения примерно на 25%. Мы все еще видим восходящую кривую просто потому, что предварительная загрузка не может быть обработана достаточно быстро. Однако арифметические операции, выполняемые основным потоком и операции загрузки памяти вспомогательного потока дополняют друг друга. Соревнование за ресурсы минимально, что дает этот синергетический эффект.
Результаты этого теста могут быть перенесены на многие другие ситуации. Гиперпотоки, часто бесполезные из-за загрязнения кэша, в таких ситуациях блистают, и их преимущества нужно использовать. Файловая система sys позволяет программе найти родственные потоки (см. колонку thread_siblings в таблице 5.3). Если информация доступна, то программе просто нужно задать родство потоков и затем обходить цикл в двух режимах: обычные операции и предварительная загрузка. Количество предварительно загружаемой памяти должно зависеть от размера разделяемого кэша. В этом примере имеет значение размер L2 и программа может запросить этот размер используя
sysconf(_SC_LEVEL2_CACHE_SIZE)
Нужно или нет ограничивать движение вспомогательного потока - зависит от программы. В общем случае лучше всего убедиться, что есть какая-то синхронизация, иначе детали планирования могут вызвать значительный упадок производительности.
6.3.5 Прямой доступ к кэшу
Один из источников промахов кэша в современных операционных системах - это обслуживание внешнего потока данных. Современное аппаратное обеспечение, такое как сетевые карты и дисковые контроллеры, имеет способность записывать получаемые или читать данные прямо в память, не задействуя процессор. Это играет решающую роль для производительности устройств, которые мы сегодня имеем, но это также создает проблемы. Предположим из сети прибывает пакет и операционная система должна решить что с ним делать, посмотрев на его заголовок. Сетевая карта помещает пакет в память и оповещает процессор о его прибытии. У процессора нет шансов на предварительную загрузку этих данных, так как он не знает, когда эти данные прибудут, и может быть даже где конкретно они будут сохранены. Результатом будет промах кэша при чтении заголовка.
Intel добавил в свои чипсеты и процессоры технологию, призванную смягчить эту проблему (см.[3]). Идея состоит в том, чтобы заполнить кэш процессора, который будет извещен о прибытии пакета, данными этого пакета. Полезная загрузка пакета здесь не критична, эти данные, в общем, будут обрабатываться функциями более высокого уровня, или в ядре или на пользовательском уровне. Заголовок ядра используется для того, чтобы принять решение о том, что делать с этим пакетом, поэтому эти данные нужны немедленно.
У сетевой системы ввода/вывода уже есть прямой доступ к память, чтобы записать пакет. Это означает, что она взаимодействует непосредственно с контроллером памяти, который возможно интегрирован в Северный мост. Другая часть контроллера памяти - это интерфейс к процессорам через FSB (в предположении, что контроллер памяти не интегрирован в сам процессор).
Идея прямого доступа к кэшу (DCA - Direct Cache Access) состоит в том, чтобы расширить протокол между сетевой картой и контроллером памяти. На рисунке 6.9 первая картинка показывает начало передачи данных с прямым доступом к памяти на обычной машине с Южным и Северным мостами.
DMA Initiated DMA and DCA Executed Рисунок 6.9: Прямой доступ к кэшу
Сетевая карта присоединена к Южному мосту (или является его частью). Она начинает прямой доступ к памяти, но предоставляет новую информацию о заголовке пакета, которая должна быть помещена в кэш процессора.
Традиционное поведение предполагает, что на втором шаге прямой доступ к памяти просто завершается присоединением к памяти. Для передачи данных прямым доступом к памяти с включенным флагом DCA Северный мост дополнительно посылает данные по FSB со специальным новым флагом DCA. Процессор просматривает FSB и, если он обнаруживает флаг DCA, то он пытается загрузить данные, направленные процессору в нижний уровень кэша. Флаг DCA - это просто индикатор, процессор может просто игнорировать его. После того, как передача с прямым доступом к памяти завершена, процессор извещается об этом.
Когда операционная система обрабатывает пакет, ей в первую очередь нужно определить какого он типа. Если индикатор DCA не игнорируется, то загрузки, необходимые операционной системе для того, чтобы идентифицировать пакет, скорее всего приведут к попаданию в кэш. Умножте эту экономию сотен циклов на пакет на десятки тысяч пакетов, которые процессор обрабатывает за секунду, и экономия составит очень значительную величину, особенно когда дело касается задержки.
Без этой интеграции между аппаратурой ввода/вывода (в данном случае сетевой картой), чипсетом и процессорами, такая оптимизация невозможна. Следовательно, при выборе платформы нужно учитывать, понадобится ли эта технология.
[1] Melo, Arnaldo Carvalho de. The 7 dwarves: debugging information beyond gdb. Proceedings of the linux symposium. 2007.
[2] Drepper, Ulrich. Futexes Are Tricky., 2005. http://people.redhat.com/drepper/futex.pdf.
[3] Huggahalli, Ram, Ravi Iyer and Scott Tetrick. Direct Cache Access for High Bandwidth Network I/O. , 2005.
| Оглавление |